

Introducing Inbox Samples: saving your data for future training samples



Today we're launching Inbox Samples, an exciting new feature that will make it much easier to improve the machine learning models built on our platform.
Now, whenever you send a new text to be analyzed by MonkeyLearn (via our API, integrations or user interface), the system will save your data within the Inbox of your model. Later on, you can use the texts in your Inbox as new training data and improve your models over time.
How to use Inbox Samples
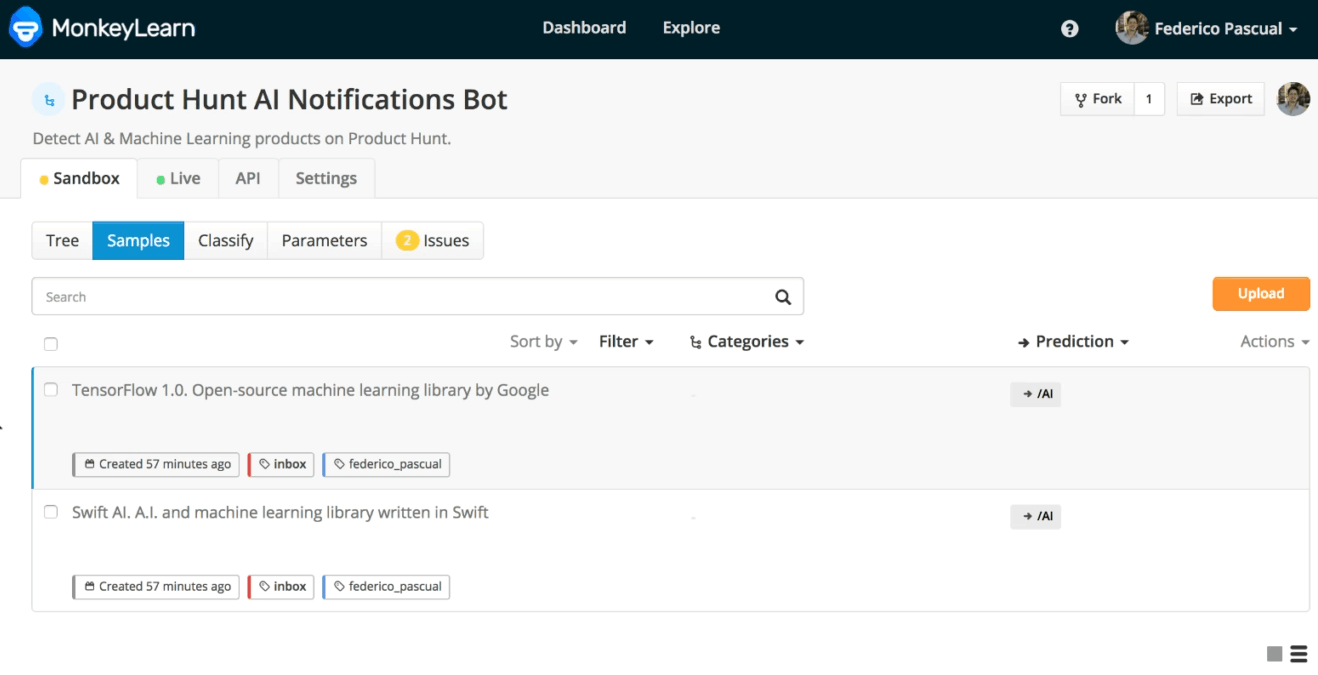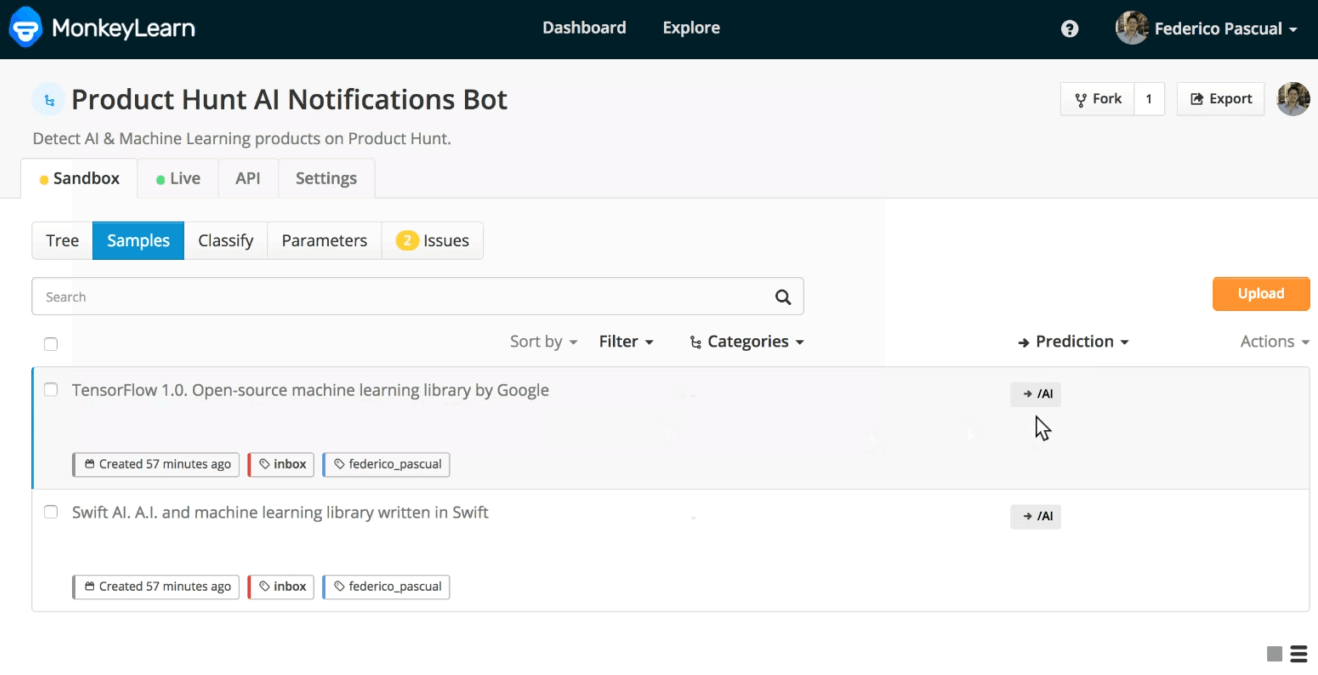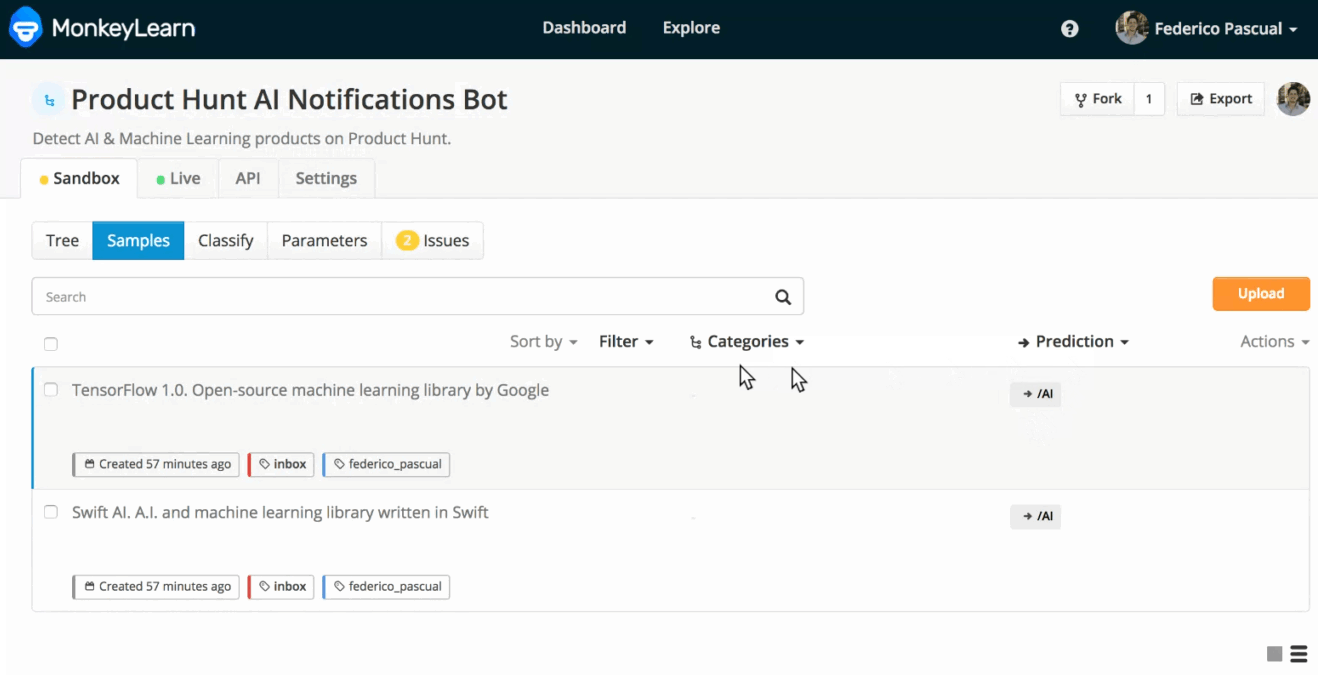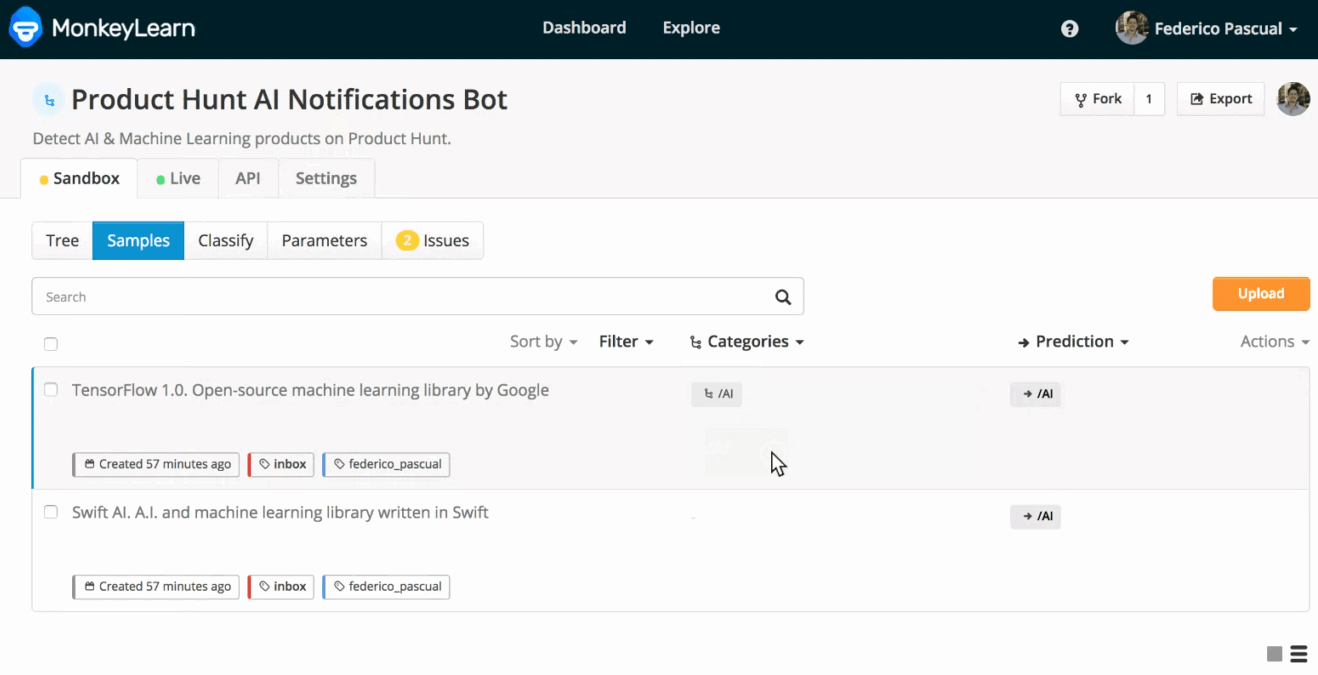
For seeing the samples within your Inbox, go to the Samples tab of your classifier and click Filter and select Inbox:
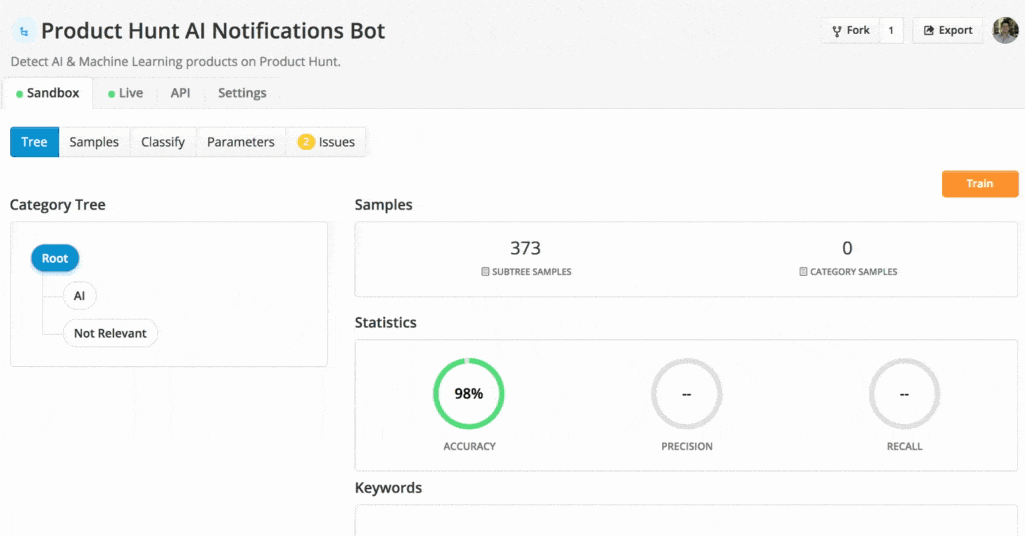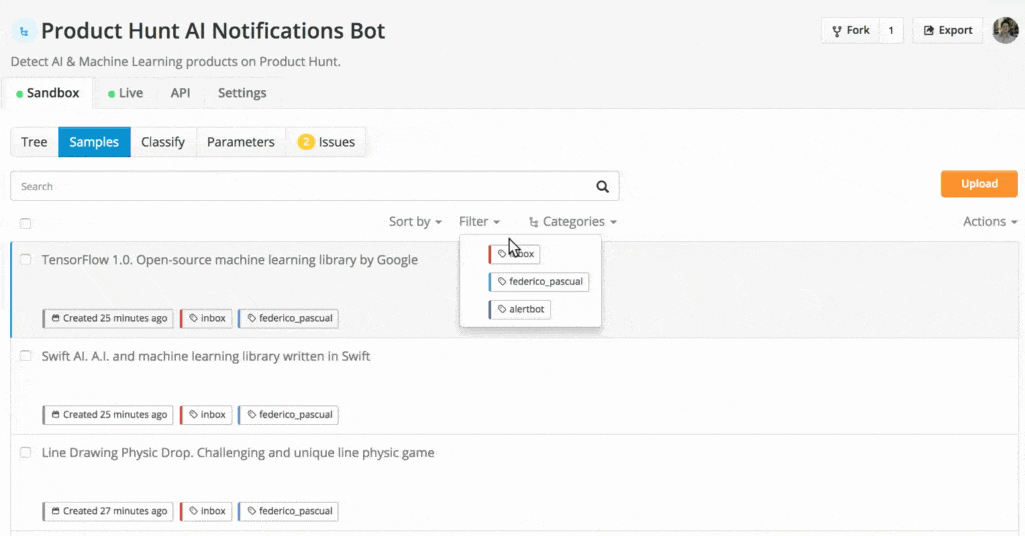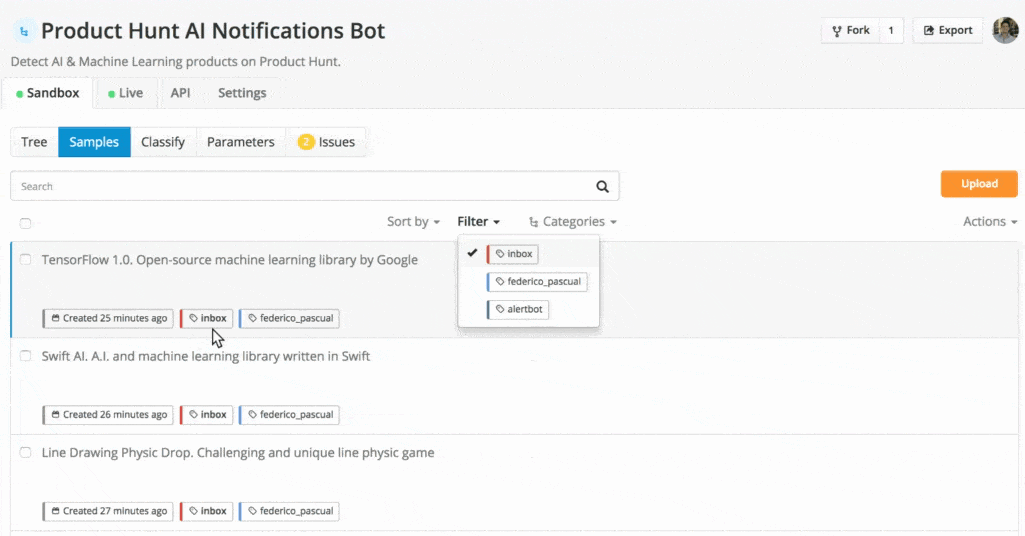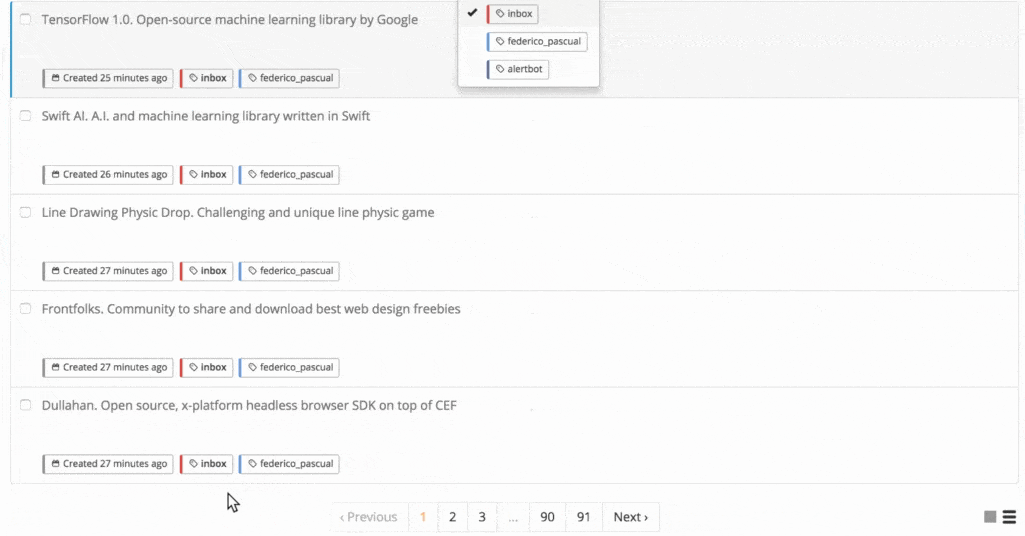
Training data saved in the inbox of a classifier.
These are all the samples within the Inbox of your model. You can see the tag predicted by the model by clicking on Tags and selecting Unassigned Samples. You can also filter these samples and only see those that got a certain prediction by clicking on Prediction and then by choosing the corresponding tag:
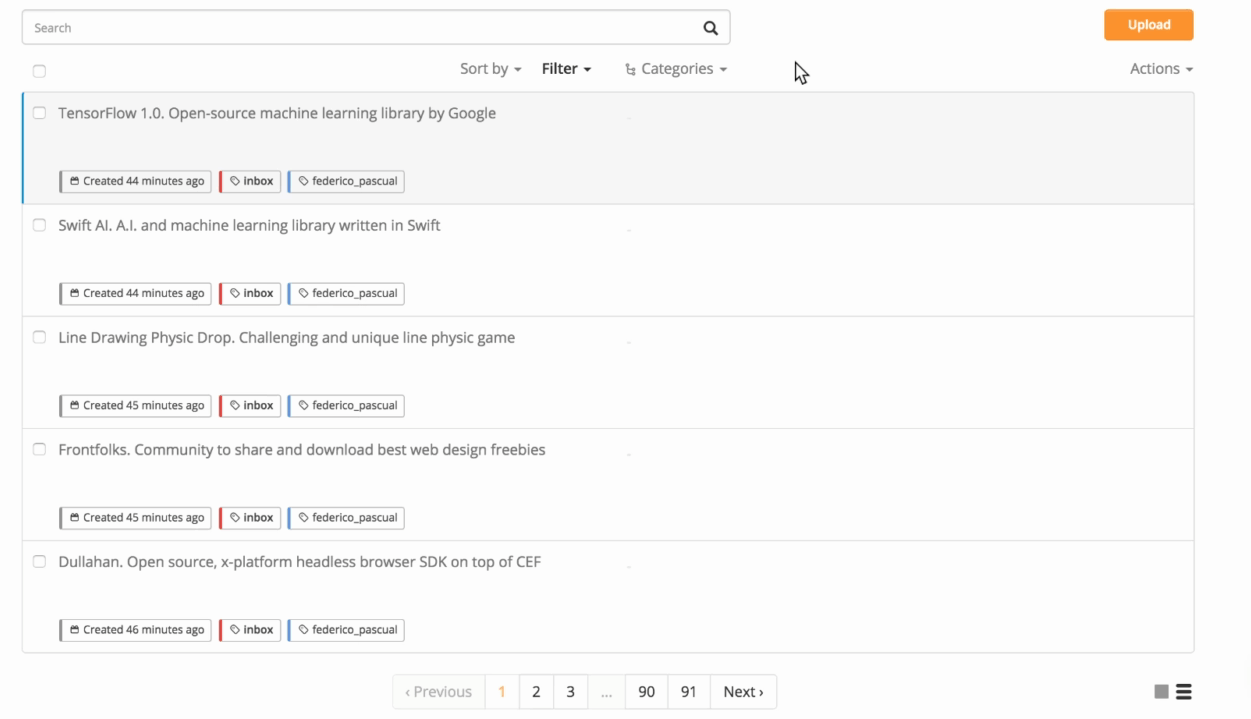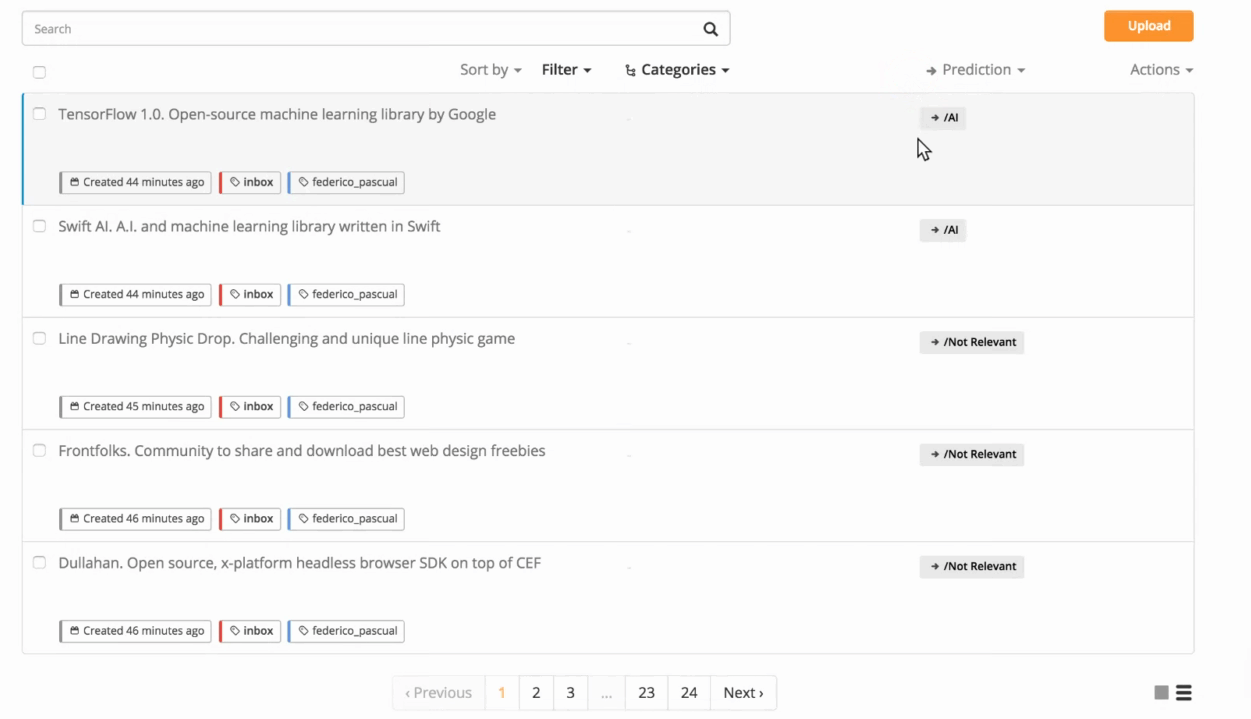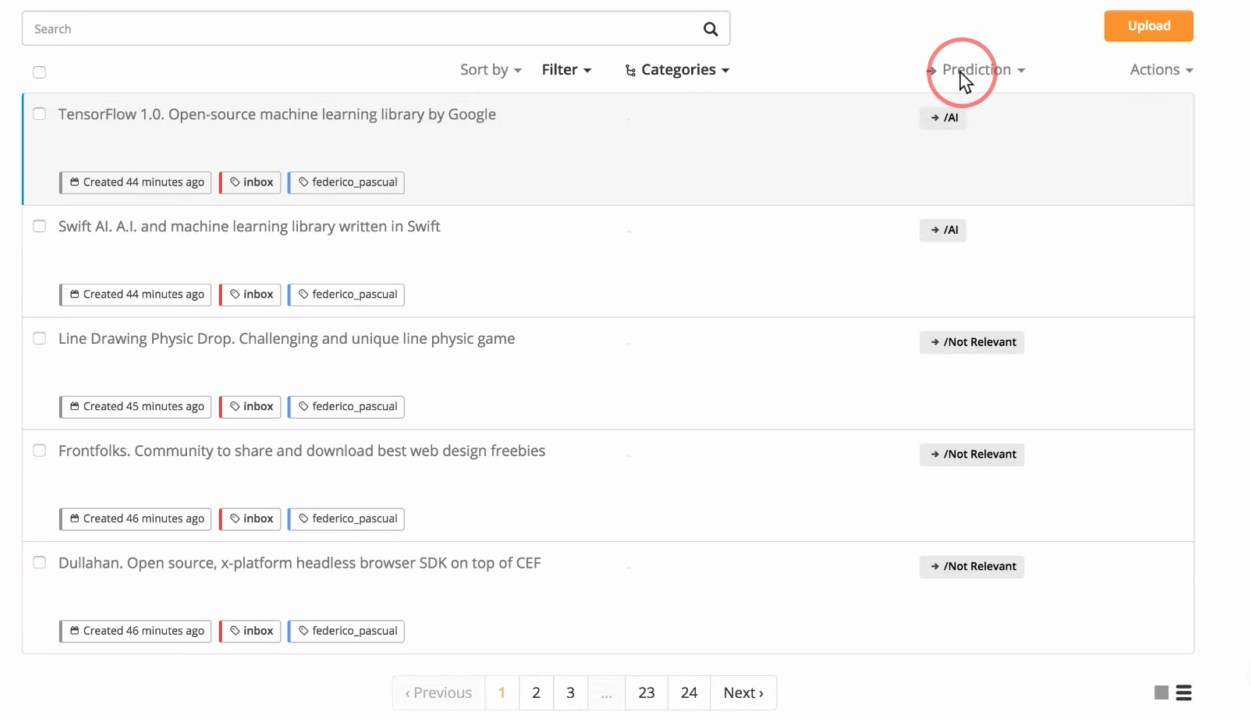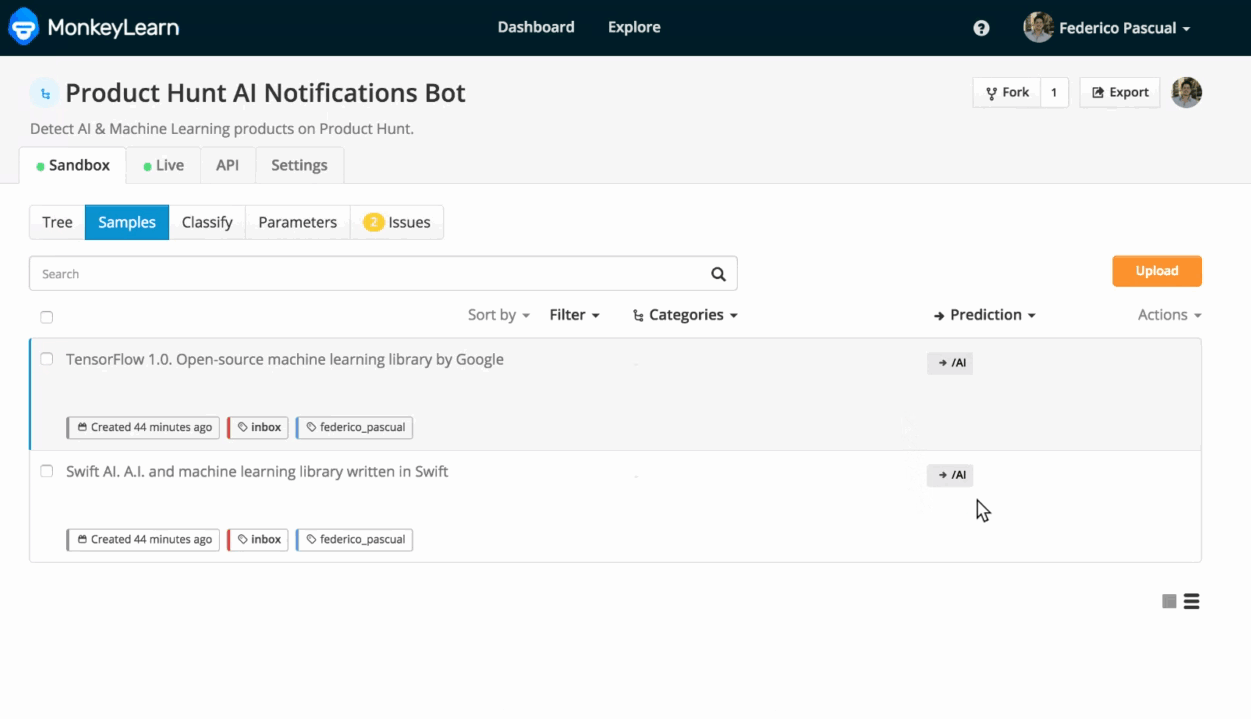
Filtering samples by prediction.
By default, these new samples don't have a tag assigned and are not used as training data by your model. For adding them as training data, you can go through them and assign the corresponding tag:
Adding a training text.
Afterwards, remember to re-train your model so it can learn from the new data.
We suggest going through the samples within your Inbox every now and then, so you can continuously improve your model and make it smarter with new data.


Federico Pascual
August 23rd, 2017
Posts you might like...














Text Analysis with Machine Learning
Turn tweets, emails, documents, webpages and more into actionable data. Automate business processes and save hours of manual data processing.
Try MonkeyLearn


