

Text Classification in Python – Build Your Own Classifier



Classifying text data manually is tedious, not to mention time-consuming.
So, why not automate text classification using Python?
In this guide, we’ll introduce you to MonkeyLearn’s API, which you can connect to your data in Python in a few simple steps. Once you’re set up, you’ll be able to use ready-made text classifiers or build your own custom classifiers.
Let’s get started!
What Is Text Classification?
Text classification (also known as text tagging or text categorization) is the process of sorting texts into categories. For example, you might want to classify customer feedback by topic, sentiment, urgency, and so on.
This process can be performed manually by human agents or automatically using text classifiers powered by machine learning algorithms.
Text Classification Tools in Python
Implementing text classification with Python can be daunting, especially when creating a classifier from scratch.
Luckily, there are many resources that can help you carry out this process, whether you choose to use open-source or SaaS tools.
Open-Source Libraries for Text Classification in Python
Python is the preferred programming language when it comes to text classification with AI because of its simple syntax and the number of open-source libraries available.
A popular open-source library is Scikit-Learn,used for general-purpose machine learning. It also comes with many resources and tutorials.
You can also use NLTKis another Python library, heavily focused on Natural Language Processing (NLP). It splits texts into paragraphs, sentences, and even parts of speech making them easier to classify.
You can also use SpaCy, a library that specializes in deep learning for building sophisticated models for a variety of NLP problems. It only has one stemmer, and word embeddings that will render your model very accurate.
After mastering complex algorithms, you may want to try out Keras, a user-friendly API that puts user experience first.
TensorFlow is another option used by experts to perform text classification with deep learning. You may also want to give PyTorch a go, as its deep integration with popular libraries makes it easy to write neural network layers in Python.
Open source tools are great because they’re flexible and free to use. On the downside, creating a machine learning model to classify texts using open-source tools is not easy.
First because you’ll need to build a fast and scalable infrastructure to run classification models. But also because machine learning models consume a lot of resources, making it hard to process high volumes of data in real time while ensuring the highest uptime.
You will also need time on your side – and money – if you want to build text classification tools that are reliable. Data scientists will need to gather and clean data, train text classification models, and test them. All this takes a lot of time and is often the most important step in creating your text classification model. At the end of the day, bad data will deliver poor results, no matter how powerful your machine learning algorithms are.
SaaS Text Classification APIs in Python
Alternatively, SaaS APIs such as MonkeyLearn API can save you a lot of time, money, and resources when implementing a text classification system. These out-of-the-box solutions require only a few lines of code, and you won’t have to worry about building complex infrastructure or learning the ins and outs of machine learning.
Just sign up to MonkeyLearn for free to use the API and Python SDK and start classifying text data with a pre-built machine learning model.
With MonkeyLearn, you can either build a custom text classifier using your own tags and data or you can use one of the pre-trained modelsfor text classification tasks. Find more information on how to integrate text classification models with Python in the API tab.
For example, to make an API request to MonkeyLearn’s sentiment analyzer, use this script:
from monkeylearn import MonkeyLearn
ml = MonkeyLearn(<<Insert your API Key here>>)
data = ["This is a great tool!"]
model_id = 'cl_pi3C7JiL'
result = ml.classifiers.classify(model_id, data)
print(result.body)
The API response for this request will look like this
[
{
"text": "This is a great tool!",
"external_id": null,
"error": false,
"classifications": [
{
"tag_name": "Positive",
"tag_id": 33767179,
"confidence": 0.998
}
]
}
]
Simple and straight-forward, right?
How to Get Started with Text Classification in Python?
The tools you use to create your classification model (SaaS or open-source) will determine how easy or difficult it is to get started with text classification. Besides choosing the right tool for training a text classifier, you’ll also need to make sure your datasets are up to scratch.
In this section, we’ll cover how to train a text classifier with machine learning from scratch. Then, we’ll show you how you can use this model for classifying text in Python.
Data for Training a Text Classification Model
Good data needs to be relevant to the problem you’re trying to solve, and will most likely come from internal sources, like Slack, Zendesk, Salesforce, SurveyMonkey, Retently, and so on. Most of the time, you’ll be able to get this data using APIs or download the data that you need in a CSV or Excel file.
Alternatively, you can use external data. To gather relevant information, you can scrape the web using BeautifulSoup or Scrapy, use APIs (e.g. Twitter API), or access public datasets:
- Reuters news dataset: Reuters compiled 21,578 news articles categorized into 135 topics. (such as Economy, Sports, and so on).
- Amazon Product Reviews: Another useful dataset to train your model, which contains 143+ million reviews and star ratings.
- Spambase: a dataset with 4,601 emails labeled as spam.
Once you’ve collected your data, you’ll need to clean your data. Without clean, high-quality data, your classifier won’t deliver accurate results.
If you show it bad data, it will output bad data.
Follow these steps on how to clean your data.
Once your data is ready to use, you can start building your text classifier.
Creating Your Own Text Classifier
If you are looking for more accuracy and reliability when classifying your texts, you should build a customer classifier.
The easiest way to do this is using MonkeyLearn.
Sign up for free and let’s get started! Follow this step-by-step tutorial to create a text classifier for topic detection. This model will be able to predict the topic of a product review based on its content.
1. Create Your Classifier
To build a machine learning model using MonkeyLearn, you’ll have to access your dashboard, then click 'create a model', and choose your model type – in this case a classifier:


Then, you will have to choose a specific type of classifier. This time, choose topic classification to build your model:


2. Upload Your Dataset
The next step is to upload texts for training your classifier. We are going to upload a CSV file with reviews from a SaaS.


3. Define Your Tags
Classifiers will categorize your text data based on the tags that you define. In this example, we’ve defined the tags Pricing, Customer Support, and Ease of Use:


4. Start Tagging Data
Let’s start training the model! You’ll be asked to tag some samples to teach your classifier to categorize the reviews you uploaded. You’ll need around 4 samples of data for each tag before your classifier starts making predictions on its own:
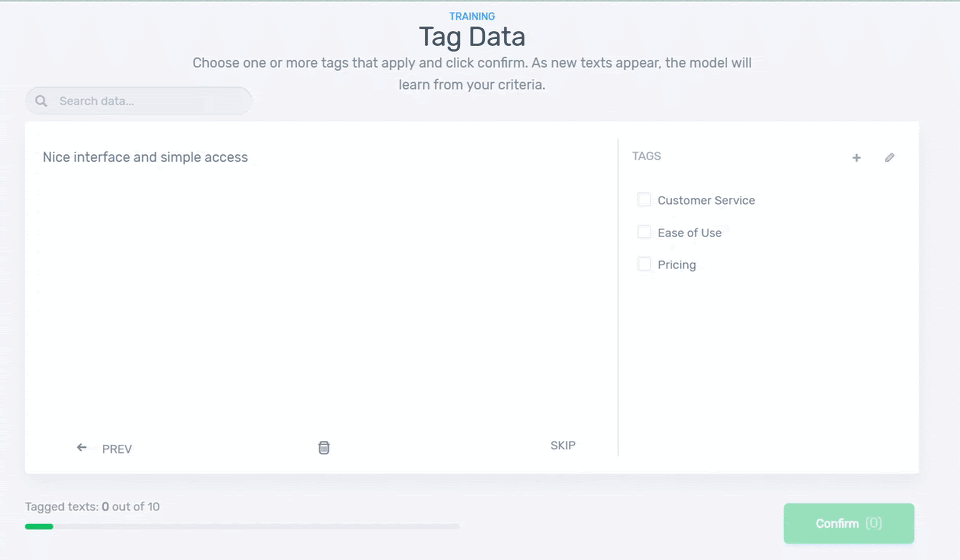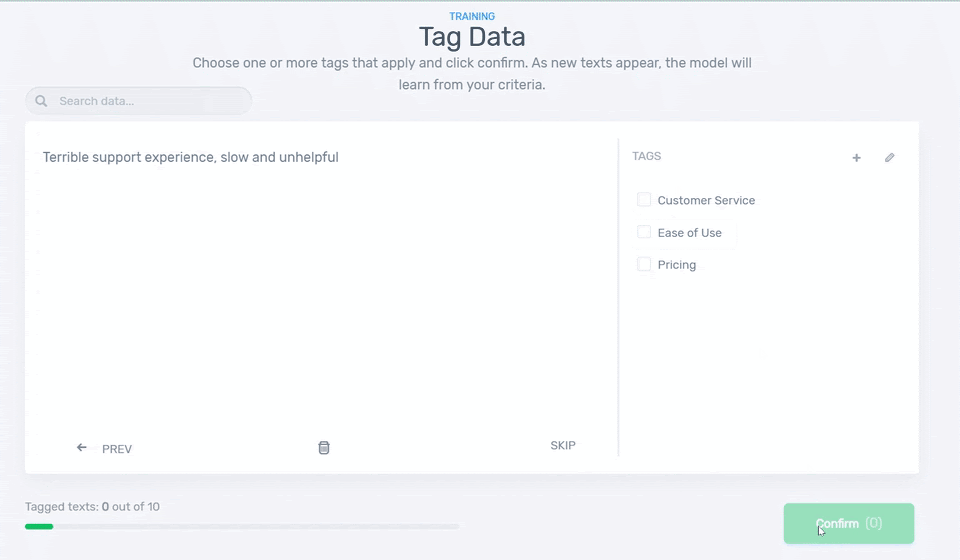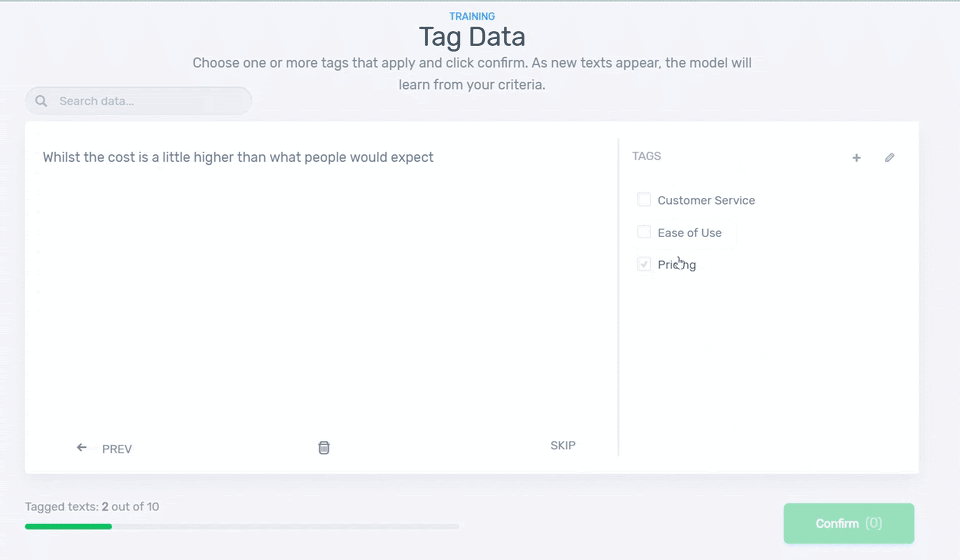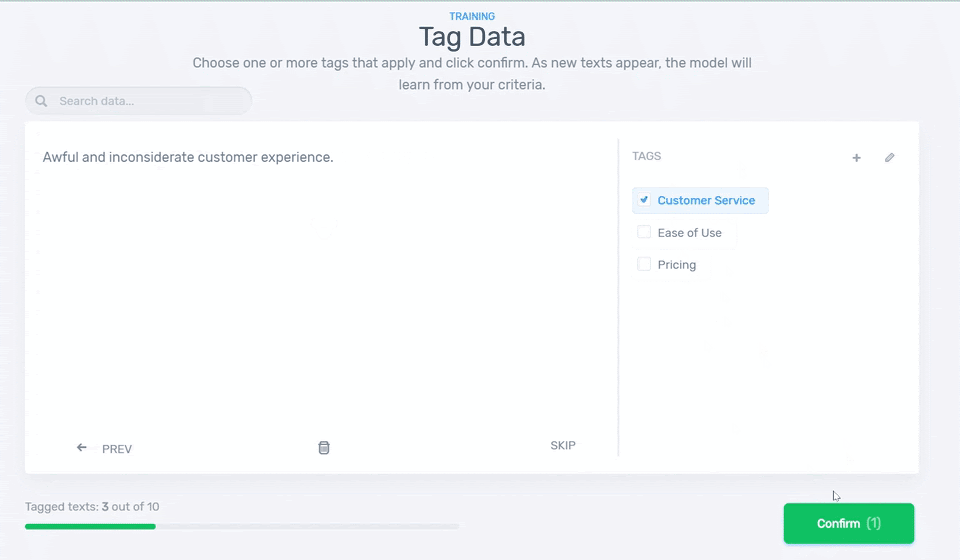
5. Test it!
After tagging a certain number of reviews, your model will be ready to go! Now you need to test it. Just type something in the text box and see how well your model works:
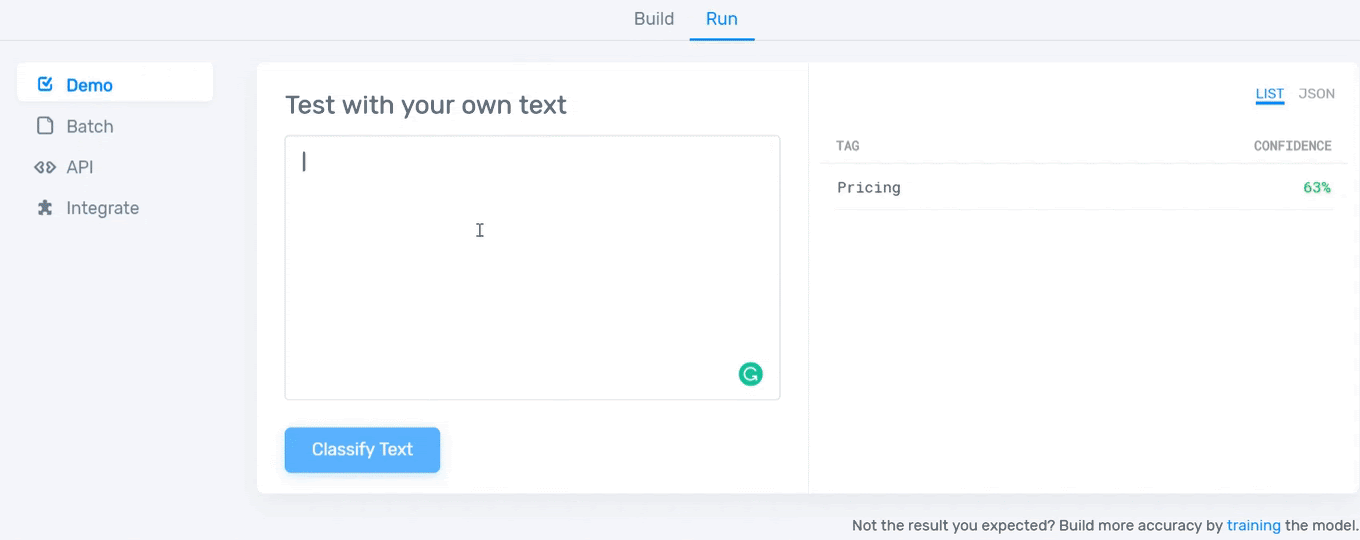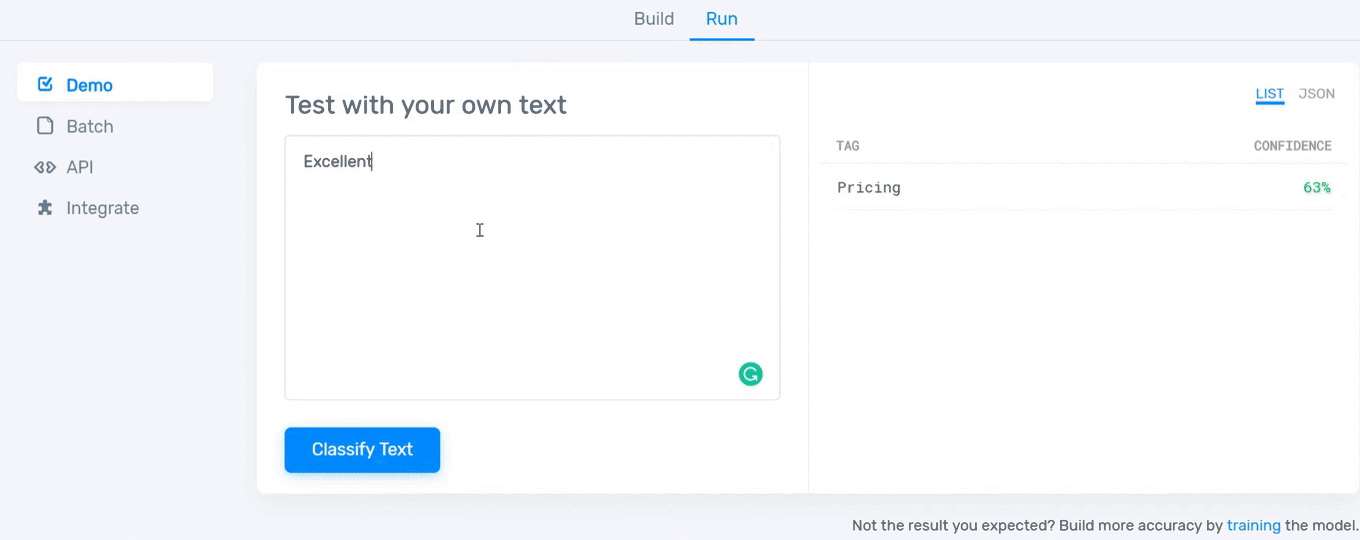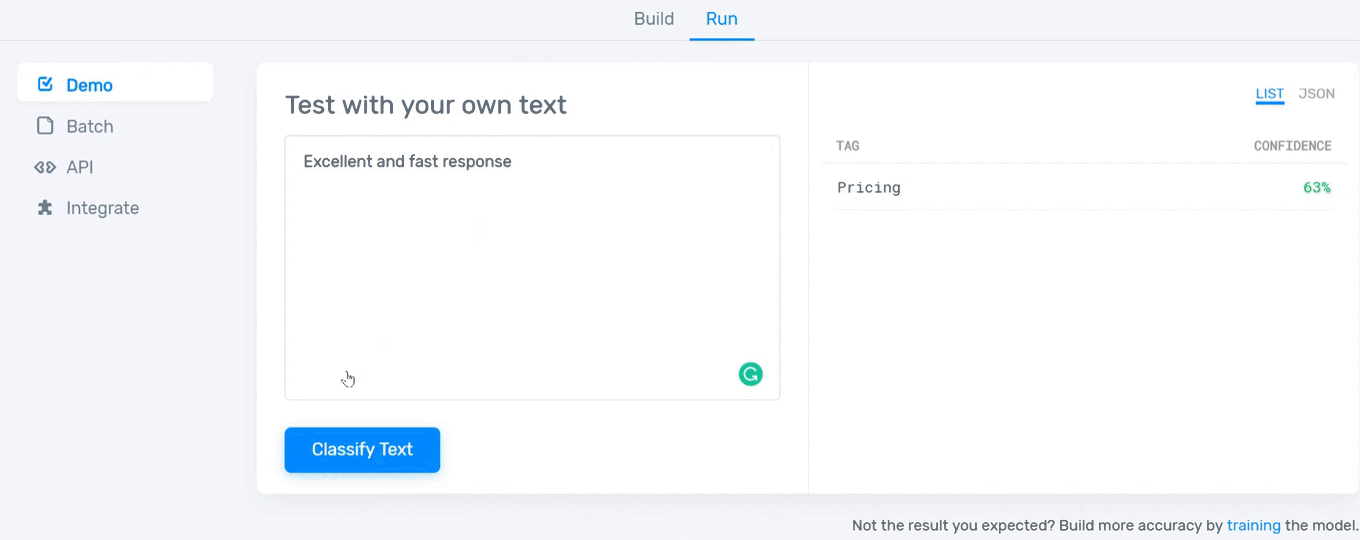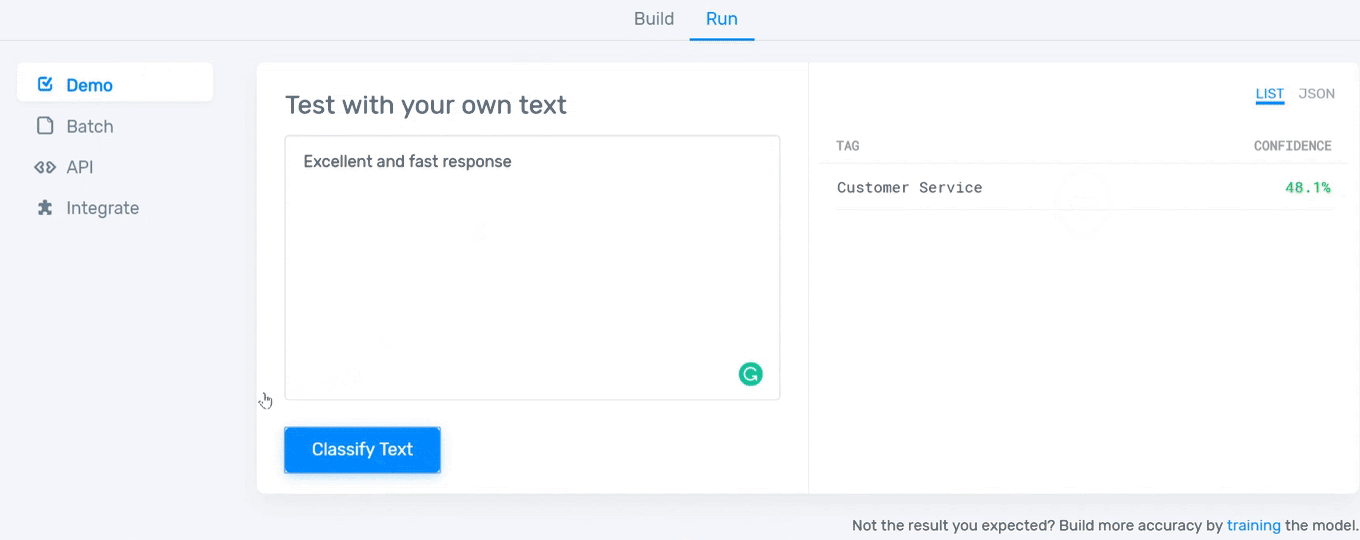
And that’s it! Now you can start using your model whenever you need it. To improve its confidence and accuracy, you just have to keep tagging examples to provide more information to the model on how you expect to classify data.
6. Calling the Text Classifier API in Python
Now, let’s see how to ‘call’ your text classifier using its API with Python. It’s not that different from how we did it before with the pre-trained model:
from monkeylearn import MonkeyLearn
ml = MonkeyLearn('<<Your API key here>>')
data = ['Customer support team is great, super helpful!', 'The UI is super confusing']
model_id = 'cl_pi3C7JiL'
result = ml.classifiers.classify(model_id, data)
print(result.body)
The API response will return the result of the analysis:
[{
'text': 'Customer support team is great',
'classifications': [{
'tag_name': 'Customer Support',
'confidence': 0.944,
'tag_id': 33767179
}],
'error': False,
'external_id': None
}, {
'text': 'The UI is super confusing',
'classifications': [{
'tag_name': 'Ease of Use',
'confidence': 0.951,
'tag_id': 33767178
}],
'error': False,
'external_id': None
}]
Wrap-up
Creating your own text classification tools to use with Python doesn’t have to be difficult with SaaS tools like MonkeyLearn. You’ll only need to enter a few lines of code in Python to connect text classifiers to various apps using the API.
Get started with text classification by signing up to MonkeyLearn for free, or request a demo for a quick run-through on how to classify your text with Python. Our team is ready to answer all your questions and help you get started!


Federico Pascual
October 14th, 2019
Posts you might like...










Text Analysis with Machine Learning
Turn tweets, emails, documents, webpages and more into actionable data. Automate business processes and save hours of manual data processing.
Try MonkeyLearn


