

Everything You Should Know about Auto-tagging Customer Feedback



Using tags to categorize customer feedback makes it possible to understand qualitative data. This process is essential for understanding your customers' issues, gaining actionable insights, and taking your customer service to the next level.
Customers leave more feedback than ever before. Eighty percent of 18-34 year olds have written online reviews – compared to just 41% of consumers over 55. And that’s great news for businesses because customer feedback gives them valuable insights about their services and/or products.
However, customers also expect more from brands.
They expect faster responses to queries, complaints, or more general feedback, and sometimes just want recognition when they leave a good review. You know, like a ‘thanks Fred, awesome review. Glad you're enjoying the product’. It’s about that personal touch or, in business terms, becoming customer-centric and understanding Voice of Customer (VoC).


If you think about all the reviews, comments, emails, tweets, survey responses and other data you’d have to go through to respond to all your customers individually, let alone personally, you’d never be able to leave the office!
Software company Atlassian was receiving 15,000 pieces of customer feedback every week, but didn’t have the resources to sort through and understand what all this data meant. So, what did they do? They created an innovative system, which involved auto-tagging their data and categorizing it by Reliability, Usability, and Functionality (RUF). By auto-tagging their customer feedback with machine learning, they were able to analyze 15,000 pieces of customer feedback in next to no time!
Wondering how you can transform your business into a customer-centric enterprise, just by tagging your feedback? Read this guide, which goes into detail about best practices for auto tagging customer feedback with machine learning, as well as various models and tools that can help you transform your customer feedback into meaningful data.
Discover how to get started with tagging customer feedback by reading this guide, or jump to one of the sections that spark your interest:
- Getting started with tagging feedback
- Automating tagging feedback with Machine Learning
- Use cases & applications
Ready to learn about tagging feedback? Let’s go!
1. Getting Started with Tagging Feedback
It’s easy to get started with tagging your feedback, but first, it’s useful to understand the benefits of tagging your data, and how you can integrate machine learning models into your business to automate the tagging process.
Why are Tags Important for Analyzing Feedback?
We’re all familiar with the saying ‘knowledge is power’, and businesses tend to have a lot of knowledge – about their industry, their products or services, and their customer groups.
However, a lot of companies fall short when it comes to gaining a deeper understanding about their customers’ issues and providing them with a seamless customer experience. Eighty-seven percent of customers think brands need to put more effort into providing a consistent experience.
Yes, there are customer experience (CX) metrics, like Net Promoter Score (NPS) and Customer Satisfaction Score (CSAT), which can help you quantify customer loyalty and satisfaction, and monitor how it changes over time. But this doesn’t tell us exactly what customers are happy/unhappy with and why. To find out the what and the why, we need to turn to customer comments, found on review sites, social media platforms, chat threads, emails and more.
However, this data is pretty useless if left unstructured. Think of toddlers learning to speak. They begin by gurgling and blurting out words, but then they learn how to string sentences together. Only then can we understand what they’re trying to tell us. Well, it’s the same with data, it needs structure before it can be transformed into meaningful results. But how can we analyze this information quickly, efficiently and accurately? By tagging feedback, of course!
How to Categorize Feedback?
Once you’ve collected, say every piece of data that mentions your brand, service, and product, you’ll want to categorize it into common themes. There are many ways in which you can categorize feedback and the approach you choose really depends on your business. Let’s take a look at how some companies are categorizing their feedback.
HubSpot says that there are typically three main categories you can group customer feedback into:
- Product feedback
- Customer service feedback
- Marketing and sales feedback
However, within each of these main categories, Hubspot also suggests creating sub-categories. Product teams might sub-categorize their feedback into Minor Bugs, Major Bugs and Feature Requests (anything from user interface to account management). Customer service teams would be interested in finding out about Billing Issues, Account Issues, and Usability Issues to detecting commonly asked questions, while marketing and sales teams might categorize feedback into Features, Pricing, and Upgrades.
Now, let’s take a look at Atlassian’s approach for organizing and categorizing customer feedback. Atlassian uses a tool that groups their feedback into three main tags – Reliability, Usability, and Functionality (RUF), so they can quickly find out what part of their customers are complaining about and why. Like HubSpot, Atlassian also uses sub-categories:
Main tag: Reliability
Sub-tags: Performance, Bugs.
Main tag: Usability
Sub-tags: Complexity, Content, Navigation.
Main tag: Functionality
Sub-tags: Tracking, Collaboration, Content Management.
By creating categories, businesses are able to break down customer feedback into more manageable requests, helping them to streamline their processes and resolve issues more effectively. Which brings us to...
Why (Great) Categorization is Important
Categorization isn’t as simple as it may seem. There are so many tags that can be used to categorize the same thing, so how do we go about creating tags that cover a wide range of feedback?
Start by thinking strategically about your business and your customers. Define a structure and criteria for your tags by asking yourself ‘what type of feedback should we focus on?’.
For example, do you want to improve upgrades over time, or identify customer service and product issues that frustrate customers? By creating tags that prioritize specific areas of customer feedback, you can respond quickly and effectively and gain insights that matter to your business.
Atlassian realized that they had to change their tagging system because they were unable to do useful or thoughtful data analysis. They didn’t have a clear structure for tagging their data, which meant teams were confused when it came to processing customer feedback. There were too many many labels, so their tagging was inconsistent, and some tags were used once and never again.
Without a consistent and controlled structure for tagging feedback, businesses struggle to get valuable insights, and once you’ve processed the feedback, it’s a lot of work to go back and re-tag open-ended answers or text with customer feedback.
It also affects your workflow. If users have to second guess which category they should tag a text with, then it’s going to take longer and results will be inaccurate. That’s why starting with a clear list of tags and a description of the type of text that can be tagged with each one will make your life a lot easier.
Best Practice for Tagging Customer Feedback
Let’s take a look at some best practices for tagging feedback, both manually (humans) and automatically (machine learning):
a) Read Through a Good Amount of Feedback First
You’ll need to create a set of tags relevant to your business, which means knowing what your customers are talking about. Start by reading through 25 - 30 pieces of feedback and jot down the topics/features/issues that appear most often.
b) Define Tags That Can Be Used Consistently
When there’s more than one tag that can be used for the same text data, the tagging process will be confusing. Both humans and machines need a well-structured tagging system that clarifies which tag should be used.
For example, let’s say you create tags for both UI and CX, and there’s a negative comment about a product feature: ‘it’s so confusing, I don’t know where I can upload new data and create a report’. Depending on the defined criteria, teammates could apply either tag, or both of them. This is why you need to start by defining your tags with one or two sentences, or guidelines, so that users are clear about which tag is used for what type of text data.
c) Remove Tags That Are Too Small or Too Niche
It’s important that your tags span a wide range of text data. Avoid anything too specific like Monthly Billing System Bug and opt for a broader topic like Reliability. This means that everything related to Reliability, like Bug Issues, Performance and Billing System, can be grouped together under one category.
Also, it’s important that tags are neutral so that positive, negative and neutral comments about the same attribute can live together under one roof! For example, instead of Good User Experience, you’d create a tag labelled User Experience or UI. In this case, we might even create a tag like Usability as a main category tag, and have more specific subcategories, such as Complexity, Content and Navigation.
Don’t create niche tags that only include a handful of cases, as machine learning models won’t have enough training data to properly learn from niche tags. If AI models are unbalanced, for example, heavily weighted in favor of tags with more training data behind them, they tend to make predictions with more popular tags over niche tags, leading to incorrectly labelled feedback.
Likewise, when manually tagging feedback, employees will forget about the niche tags and opt for the tags they use most frequently. Leading to inaccurate results and less meaningful insights.
d) Not Every Piece of Feedback Needs a Tag
Remember, you don’t need to tag every piece of feedback. Some customers will leave comments about topics that are unique to them. Businesses are better off tagging recurring topics/issues within customer feedback so that they respond to a larger customer base and create a bigger impact when resolving issues.
e) Keep Tags to a Minimum
When tagging, think quality over quantity. We’d recommend no more than 15 tags so your team can be consistent with their tagging. Imagine if they have hundreds of tags to choose from – first of all, they’re not going to tag data consistently, and secondly, scrolling through a long list of tags is going to be time-consuming. More importantly, your data will suffer. You won’t receive an accurate analysis about which areas within your business need immediate attention, and which ones are succeeding.
f) Embrace Hierarchy
To helps teammates (and machines) sort through tags more easily, we suggest creating a hierarchy, with one main tag and several subtags. Let’s say customer feedback for MonkeyLearn talks about Training Models and Integrations, these should be subtags of Functionality. In machine learning, having a solid hierarchical structure helps algorithms make more accurate predictions. Take a last look at your tags, see if you can group any together, and make life much easier for your team!
g) Use Different Tags for Each Descriptor Type
We often use sets of words to describe one thing, for example, company descriptions might read:
- A B2C focusing on banking
- A B2C offering software solutions
- A B2B in agriculture
Here, we have two types of descriptor in each company description – client type (B2B, B2C) and industry type (agriculture, software, banking). Each descriptor type should get its own tag hierarchy, so this information can be analyzed separately, and yield different information depending on who the company sells to and which industry they’re in.
In machine learning, instead of creating one classification model that contains all the tags (B2B, B2C, Software, Agriculture, Banking), you’d train two different models as there are two ways to classify or group text, and therefore, two classification problems that require different solutions. Also, keeping these models separate helps avoid confusion, and teammates can deliver insightful data about different aspects of a business.
2. Automating Tagging Feedback with Machine Learning
We’ve explained why tagging feedback is important, but we haven’t gone into detail about how to do it at scale.
Why is this important? Simply, because we’re drowning in information and it’s not humanly possible to read through and tag 15,000 comments every week.
Why do we need to read all our customer feedback? Customers are the backbone of business. Without them, we wouldn’t know if our products and services were working, and/or if they needed improving. By analyzing every piece of customer feedback, businesses can gain invaluable and accurate insights about their products and services, as well as reduce their churn rate. But to do this, businesses need to implement auto-tagging with machine learning into their business models.
Let’s give you a quick debrief...At MonkeyLearn, we use two machine learning models to tag and analyze text – classifiers and extractors. Our models are very simple to use and can help organize customer feedback. Let’s say you wanted to know how customers felt about a feature you’ve just released. You’d create a sentiment analysis model to classify feedback into positive or negative, an aspect classifier to identify the theme or topic and a extraction model to understand the most relevant keywords used for talking about this particular feature.
How do text analysis models work? Through machine learning. We need to teach models how to differentiate texts by creating tags, then we need to train them using the appropriate tags for each piece of text. Once we’ve shown a model a few examples, machine learning will kick in and you’ll notice that your models start predicting tags on your customer feedback by themselves.
Why is Auto-tagging Important for Analyzing Feedback?
Before going into more detail about why auto-tagging with machine learning is important, let’s look at some cold, hard facts! In early 2012, Twitter was seeing roughly 175 million tweets every day while more than 2.5 billion comments are posted on Facebook Pages every month. That’s a lot of data for businesses to go through, and the only way it’s possible is by auto-tagging feedback with machine learning. Let’s break it down:
Scalability
Auto-tagging gives businesses the opportunity to analyze large quantities of data in no time at all. Let’s put the benefits of auto-tagging into context; decoding the human genome originally took 10 years to process. Now it can be achieved in just one week. That’s a lot of time saved and a lot of data processed (about 3 billion pieces!) thanks to machine learning. Now imagine how auto-tagging feedback can help your business!
Real-time Analysis
Data has gone from scarce to superabundant, meaning businesses are constantly bombarded with new information. The great advantage of auto-tagging feedback with machine learning is that it can be done 24/7, so more pressing issues can be detected swiftly and dealt with accordingly. It’s great news for customers too. By tagging feedback and directing it to the right team member as quickly as possible, businesses will make customers feel like they’re being listened to, and their problems being solved.
Consistent Criteria
Tagging feedback manually isn’t just time-consuming, it’s also frustrating for team members. And when tasks are long and tedious, it’s difficult for us to concentrate and be consistent. Another human trait that affects consistency is emotion. Teammates might tag the same feedback differently, depending on their background, beliefs, and experiences. Machines, however, follow set guidelines and will always tag conflicting data entries based on the same criteria.
Deeper customer understanding
Depending on how you tag your feedback, you can gain as little or as much insight from customer feedback as you like. We’ve already covered the importance of defining your tags to create a well-structured tagging system, but this best practice is also important for gaining deeper customer insights. By using sub-tags within main tags, we’re able to analyze every detail within a text, not just the text as a whole.
For example, a main tag for an app might be Reliability, which describes the overall context of a piece of text. However, if we want to know exactly which feature of the app the Reliability tag refers to, as well as if the text is speaking positively or negatively about a feature, we could create sub-tags such as Performance and Bugs.
What is Aspect-Based Sentiment Analysis?
Aspect-based sentiment analysis is a machine learning technique that analyzes various aspects (topic customer is talking about) within customer feedback and allocates each one a sentiment (positive or negative). It means we can find out how customers feel about different aspects of a product or service. Aspects are the features or attributes of a product or service, for example, the Ease of Use, User Experience, Design, and Integrations.
How to Do Aspect-Based Sentiment Analysis
You’ll be able to build your aspect-based sentiment analysis models in seconds with MonkeyLearn – no code needed! But before we show you how, let us explain how it works.
i) Preprocessing Data With Opinion Units
Preprocessing data with opinion units is essential before doing aspect-based sentiment analysis. It might sound complicated, but it’s pretty easy to get your head around. Opinion units are fragments of text that usually contain one sentiment and multiple aspects. Customer feedback is a great example because it usually contains more than one opinion about a product within the same piece of text.
Here’s an example of a short review for Evernote that contains two opinion units:
'Good for notes but doesn't sync across all the devices instantly.'
It’s easy for humans to detect that there are two opinion units but harder for machines, which is why we need to preprocess feedback to help machine learning models detect opinion units.
So, in this case, we’d separate ‘good for notes’, which is positive (sentiment) about notes (aspect) and ‘doesn't sync across all the devices instantly’, which is negative (sentiment) about device synchronization (aspect). By tagging training data and connecting sentiments to specific aspects, otherwise known as preprocessing data with opinion units, you’re able to gain richer insights.
See for yourself how opinion units work with this pre-trained opinion unit extractor:


We’ve shown you why opinion units are important, not just for tagging data while training your models, but also when using a model to make predictions on new data. Why not have a go at building your own? Just follow our useful guide on how to train your own text extractor here.
Now that we have our opinion units, it’s time to learn how to build your own sentiment and aspect models! Once you’ve got your two models up and running, you’ll be able to combine them to do aspect-based sentiment analysis on customer feedback – a bit like crossing two Ts with one stroke of the pen, making your job quicker and easier!
First, let’s start with the sentiment analysis model, and then we’ll build the aspect classifier.
ii) How to Create a Sentiment Analysis Model:
1. Create your model:
Go to your Dashboard and click on ‘Create Model’, then choose ‘Classifier’:


2. Choose ‘Sentiment Analysis’ from the list:


3. Upload training data:
Upload data, internal or external and in various formats (CSV or Excel), or from Front, Gmail, Zendesk, Promoter.io and other third-party integrations offered by MonkeyLearn:


Remember, this data is super important because you’ll use it to train your models. The richer the data, the more accurate your model will be.
4. Start training your model:
Start tagging texts manually using the appropriate predefined tags (positive, neutral, negative). Check out this example below:
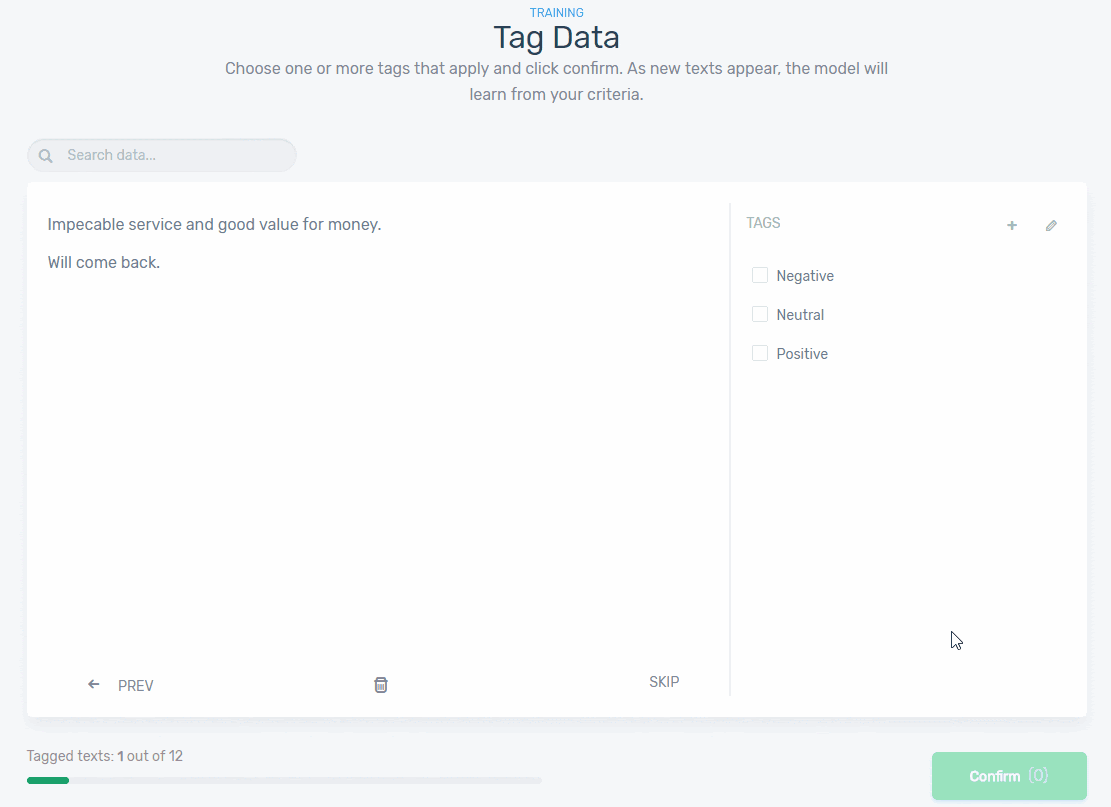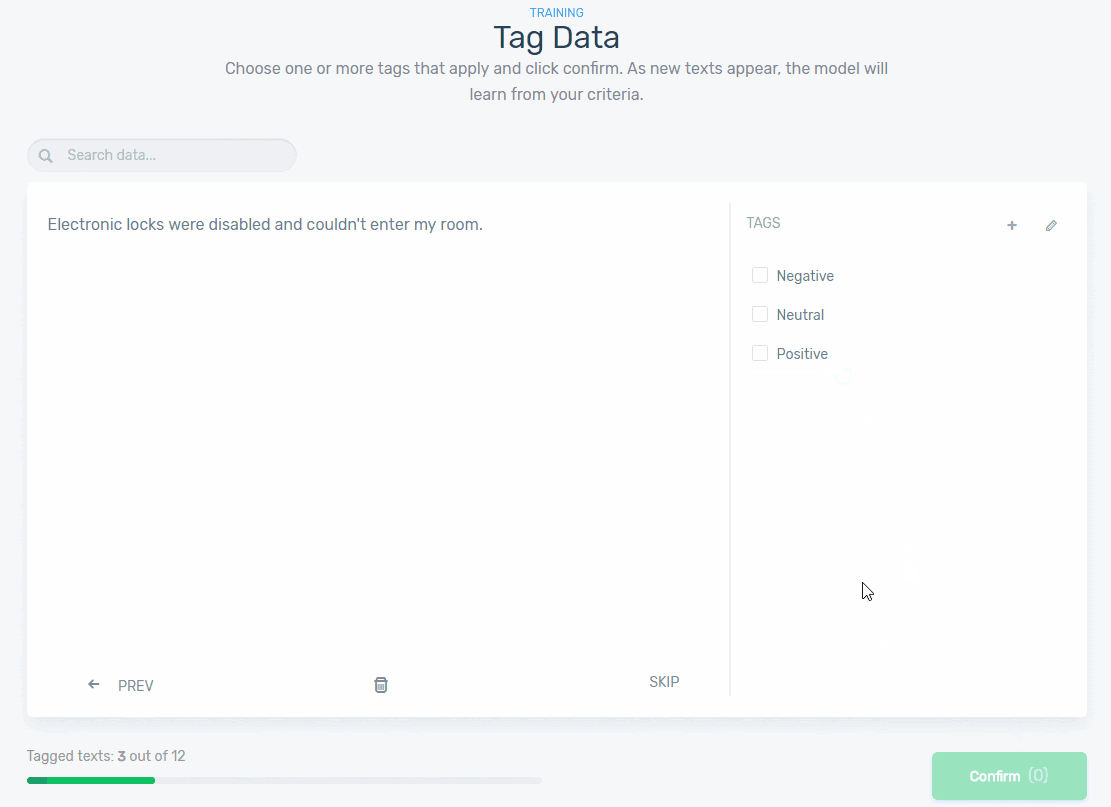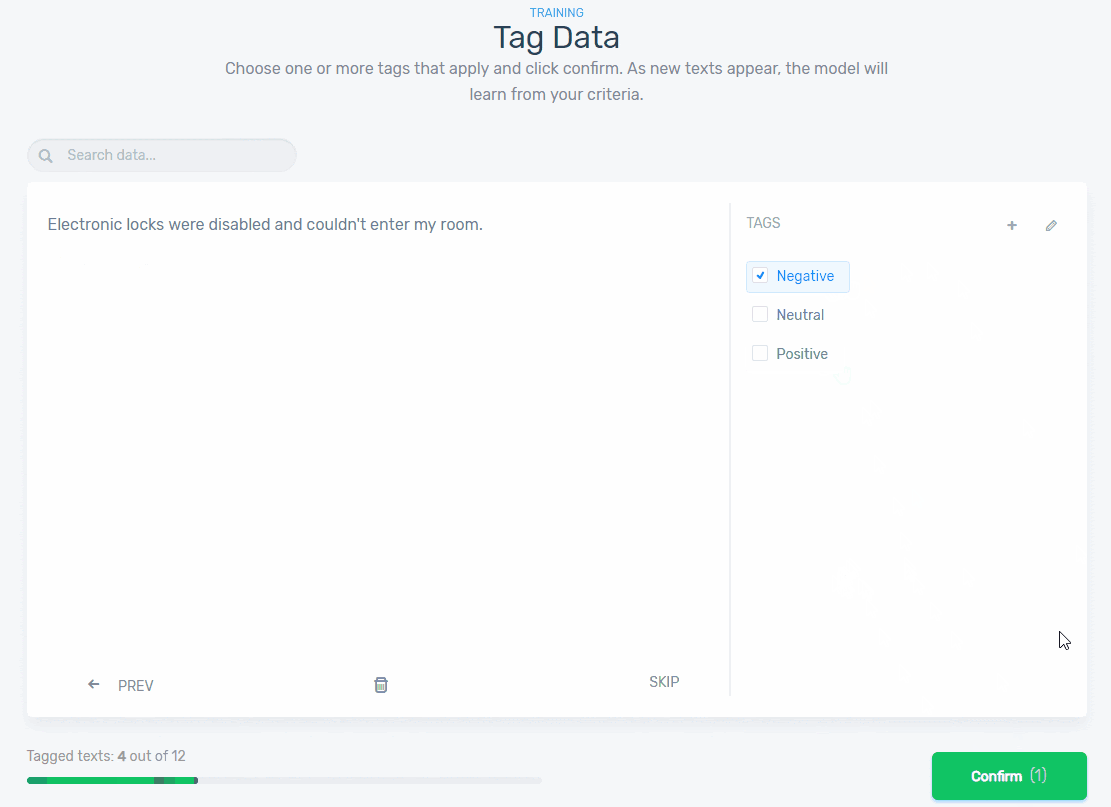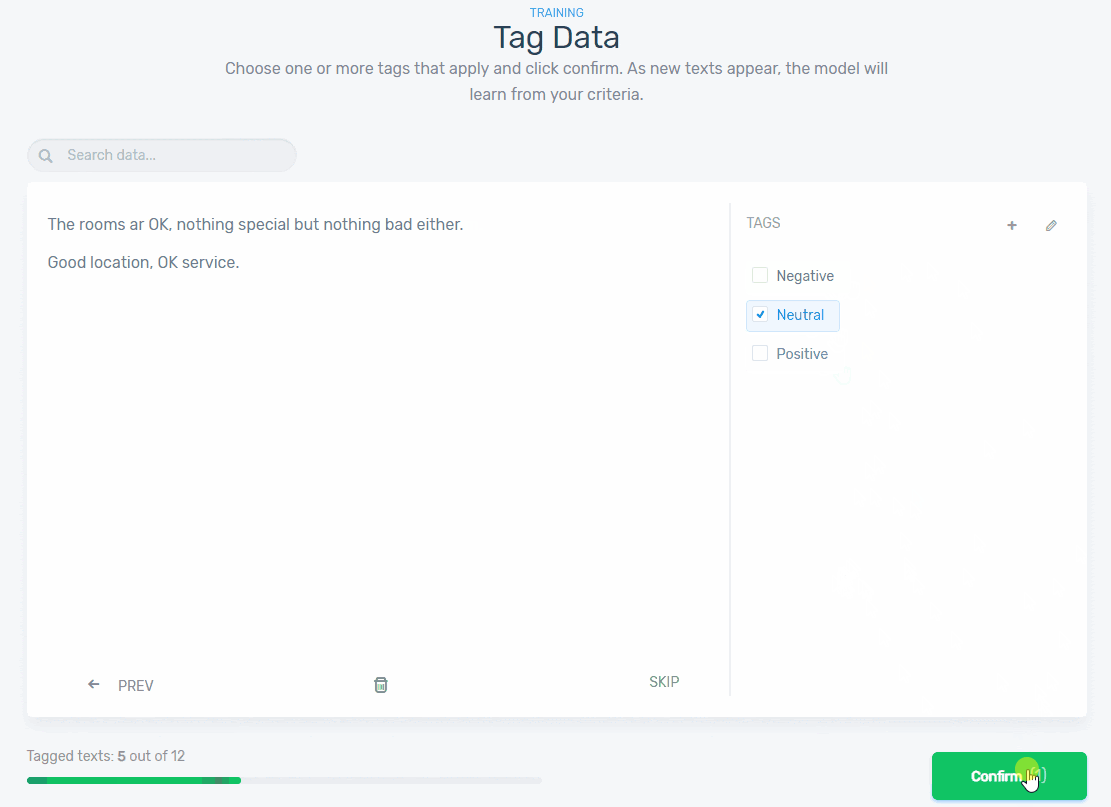
The more time you spend training you model, the more accurate and confident your model will be at making predictions because it’s getting smarter. After tagging a handful of examples, you’ll notice that some customer feedback data has already been tagged. Don’t worry, that’s not a supernatural being! That’s machine learning taking over!
5. Test your sentiment analysis model:
Once you’ve trained your model with a set of examples, you’ll be ready to test it. Just go to the ‘Run’ tab, write or import new data samples, and check that your machine learning model is classifying text correctly:
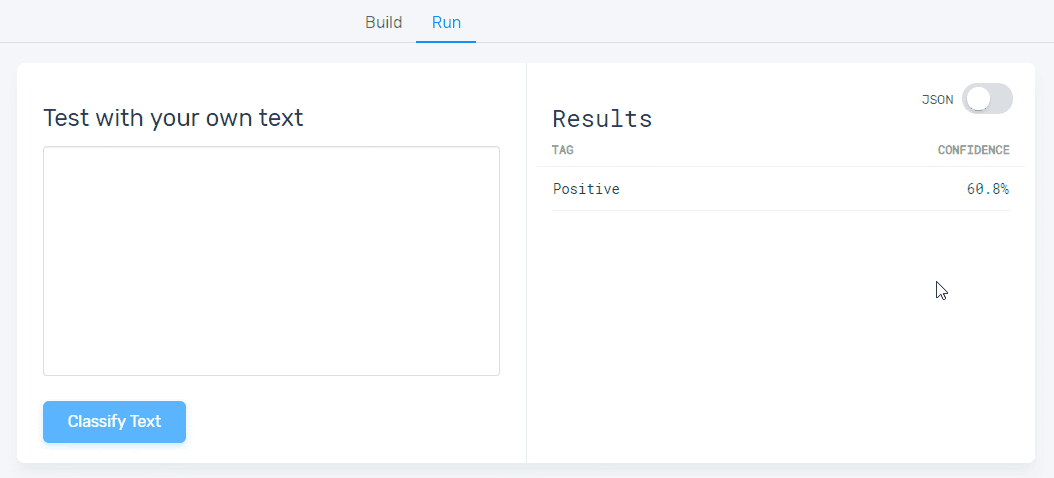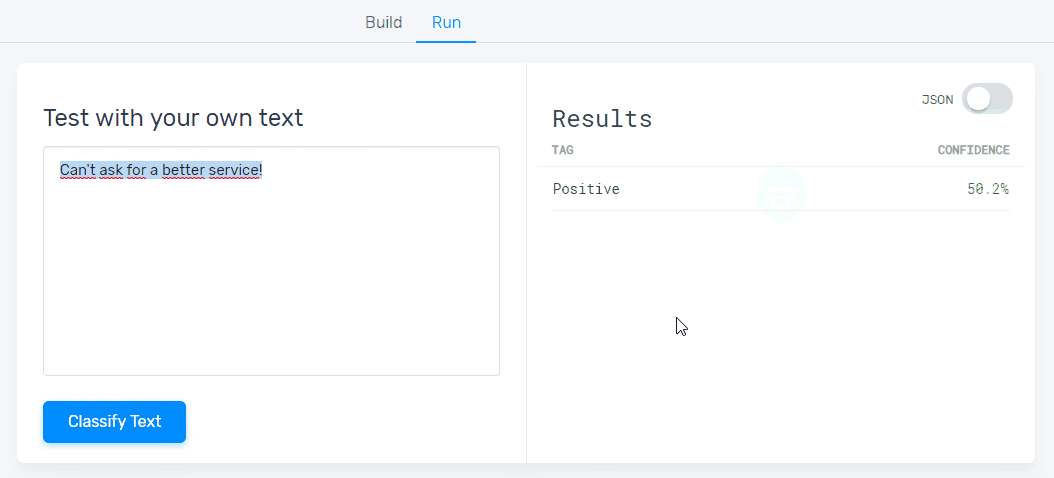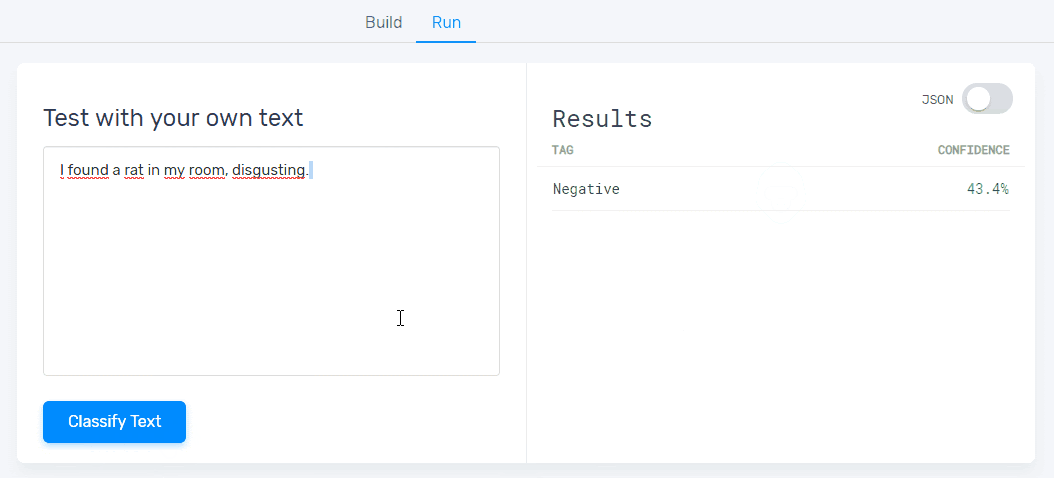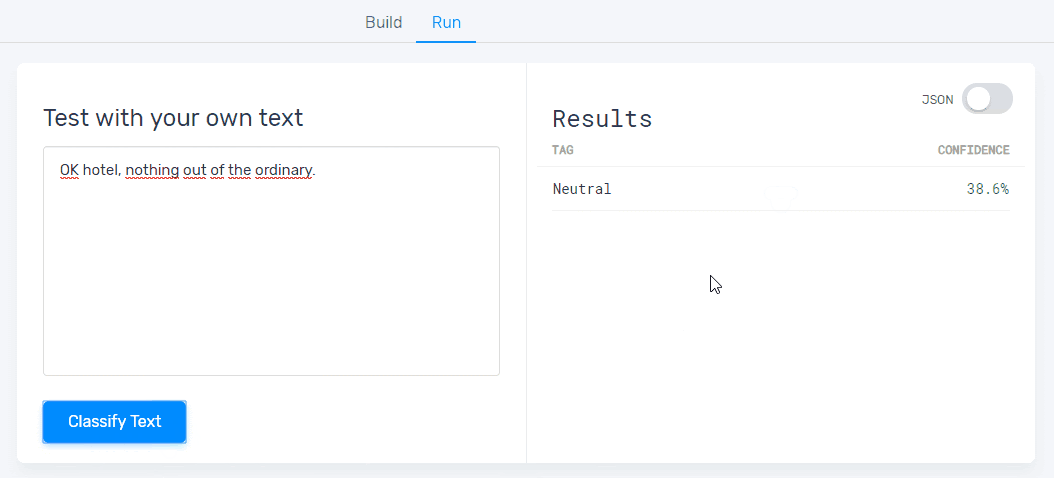
If it’s still a bit rusty, keep training it by going to the ‘Build’ tab.
6. Put your sentiment classifier to work:
Choose how you want to use your model to analyze new data. You can upload CSV and Excel files with customer feedback:


Or you can use one of our integrations:


If you know how to code, you might want to use MonkeyLearn API to analyze new data:


iii) How to Create an Aspect Model:
When you create an aspect model, you’ll need to define a set of tags that are relevant to your customer feedback. Remember, it’s important to take time defining your tags, so that you can create a well-structured tagging process:
1. Create your model:
Go to your Dashboard and click on ‘Create Model’, then choose ‘Classifier’:
2. Choose ‘Topic Classification’ from the list:
3. Upload training data:
By uploading data, you’ll be able to start training your model. You can import data from CSV or Excel files, or from Front, Gmail, Zendesk, Promoter.io and other third-party integrations offered by MonkeyLearn:


4. Define tags with different aspects to create a well-structured tagging process for both humans and machines:
5. Start training your model by tagging texts manually using the appropriate tags. Check out this example below:
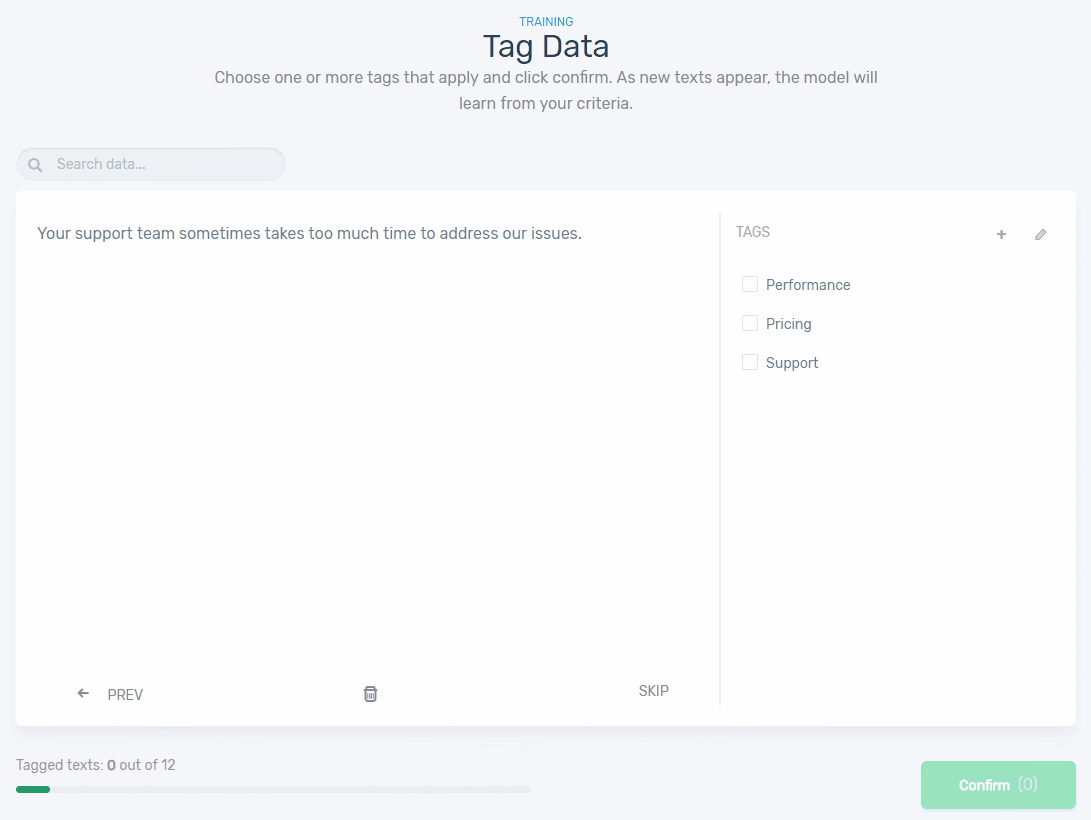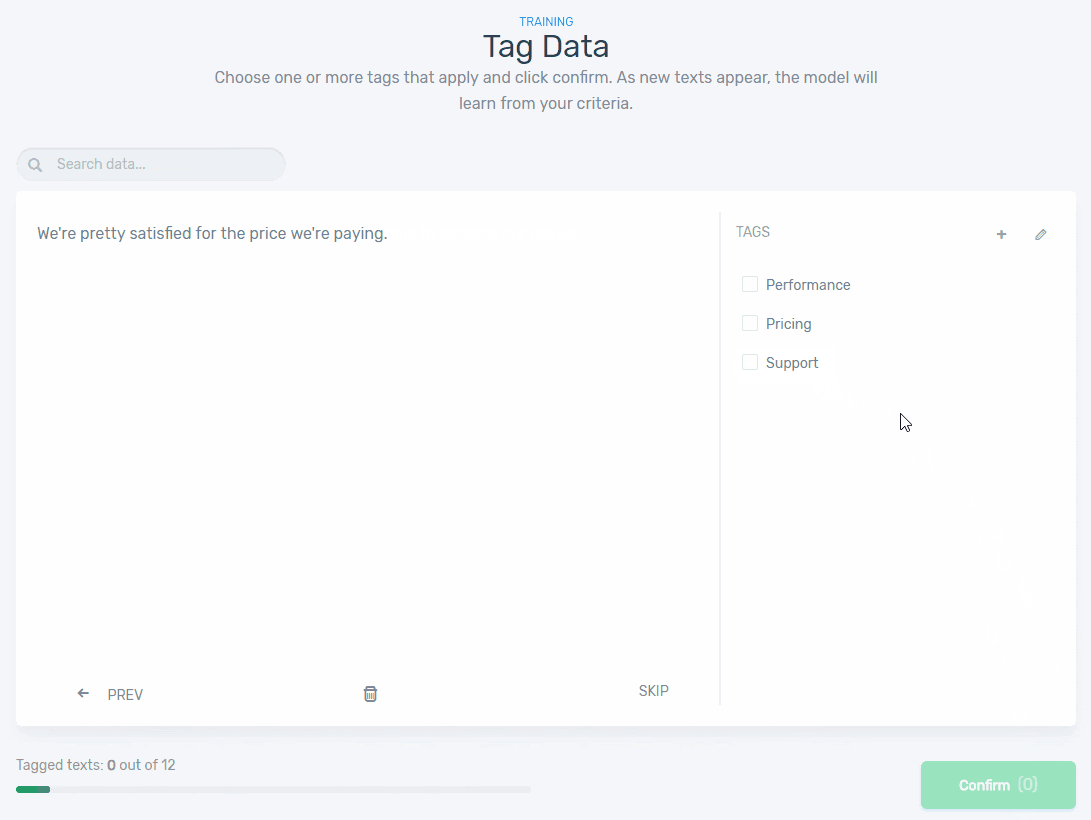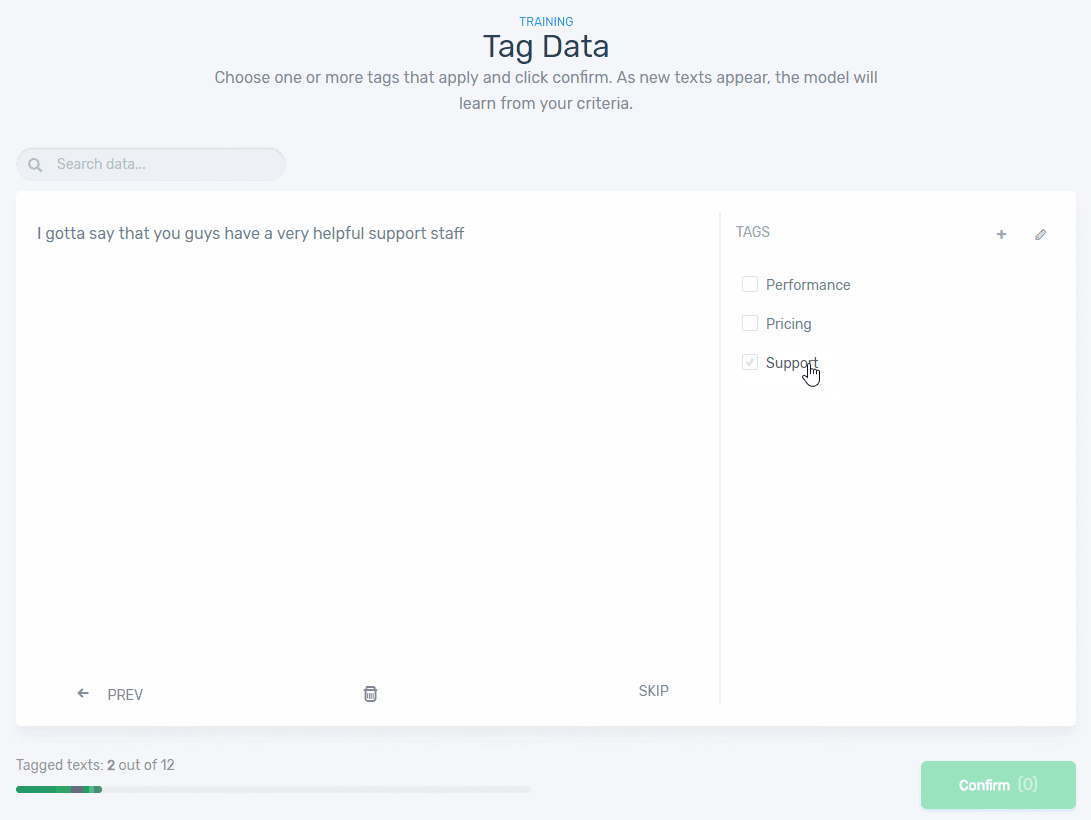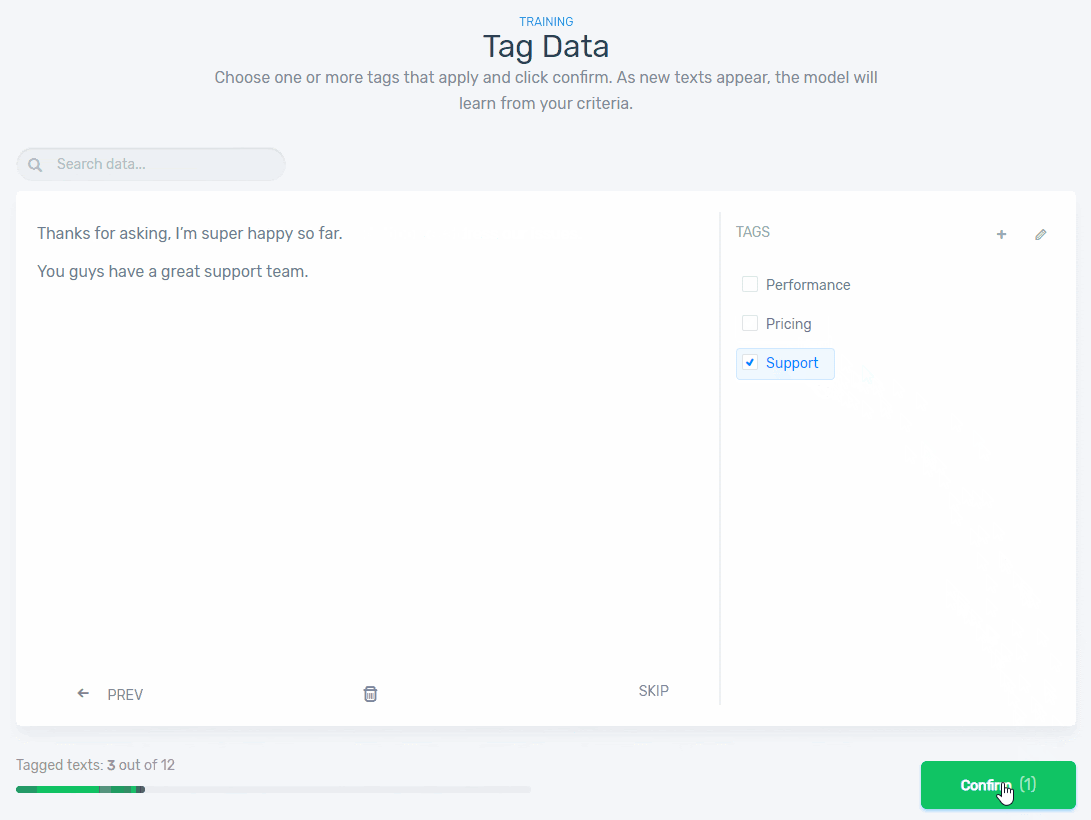
Once you’ve tagged enough examples of text, your machine learning model will continue the tagging process without any manual input. The more examples you train your machine with, the better it will be at predicting the aspects of your feedback.
6. Test your aspect-based model:
Time to take your machine learning model for a spin! Go to the ‘Run’ tab and write some new data samples to see if your model tags them correctly:
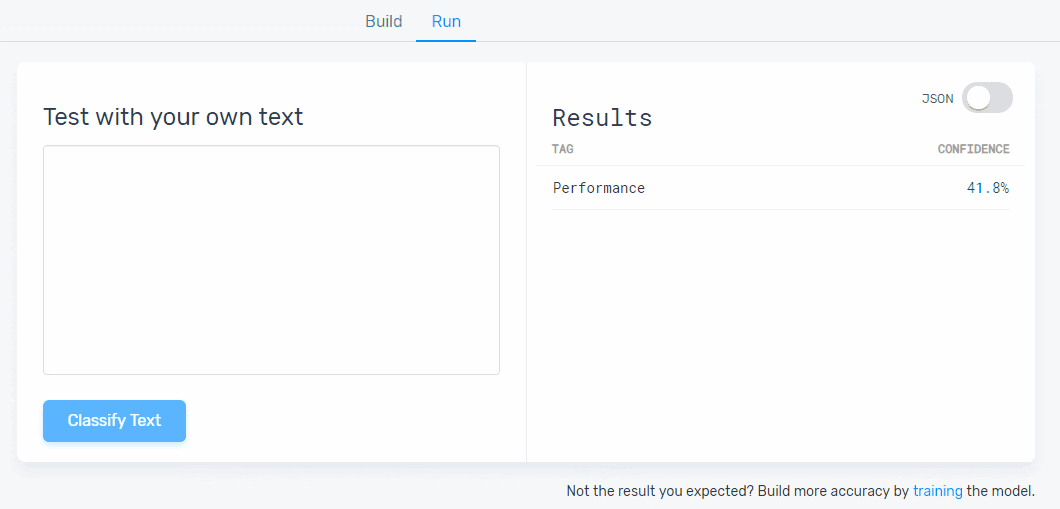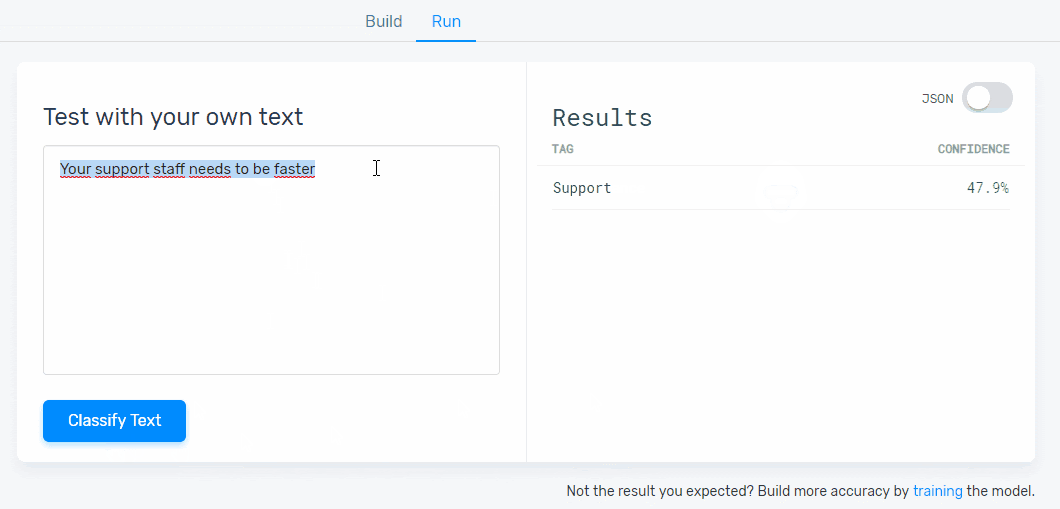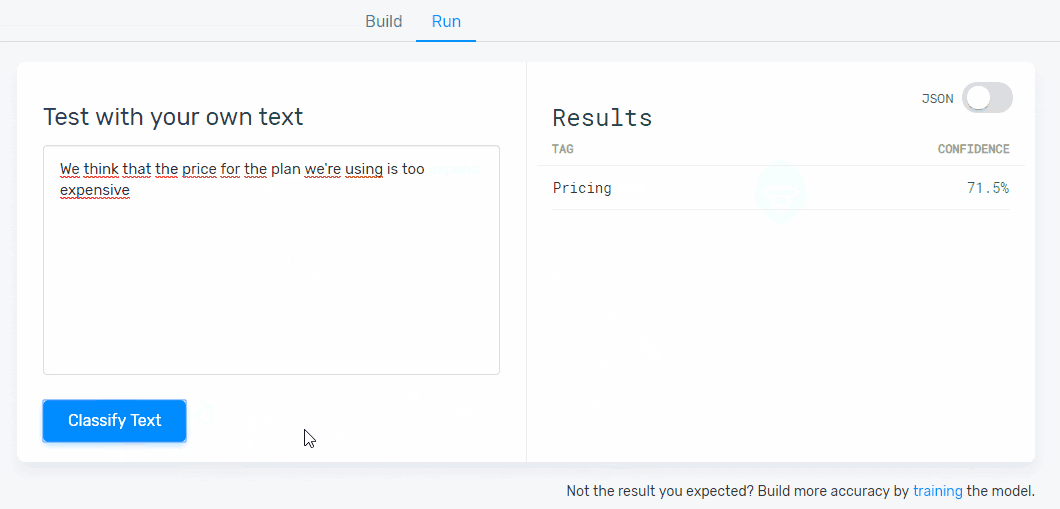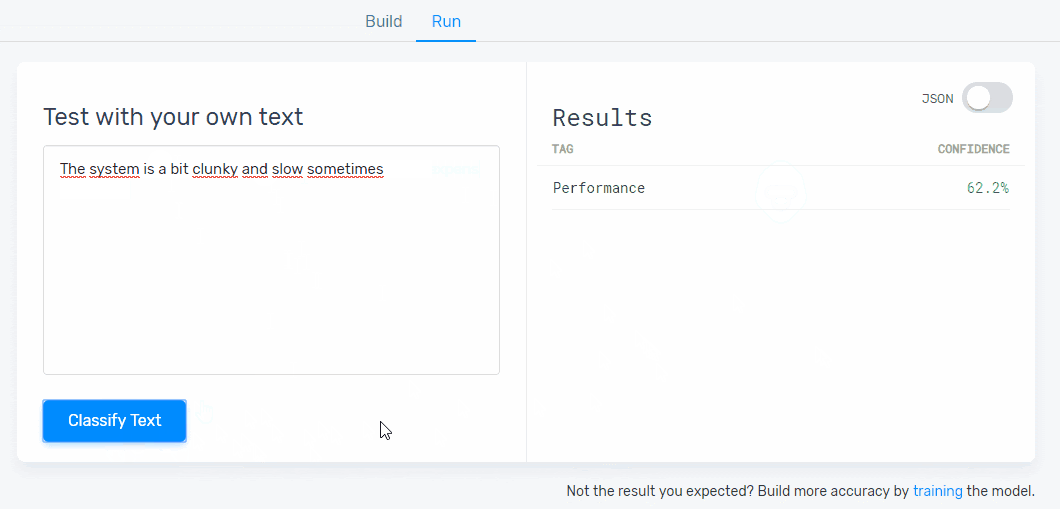
If your model needs extra training, go to the ‘Build’ tab and continue tagging data examples. You’ll be able to tag this new data until you’re happy with the predictions your model is making.
7. Put your aspect classifier to work:
Give your aspect classifier new feedback to analyze by uploading data from CSV and Excel files, or use one of our integrations. Another way to use this model to analyze new feedback is through MonkeyLearn API, which can be coded in one of the following: Python, Ruby, PHP, Javascript, or Java.
Nice one! You’ve learned how to run an aspect-based sentiment analysis. We know it’s a lot of information to take in, so let’s just summarize the steps you need to take to get the most out of your feedback:
- Separate feedback into opinion units
- Analyze opinion units using a sentiment analysis classification model.
- Analyze opinion units using an aspect-based classification model
And there you have it… Three sets of data from one set of feedback – opinion units, sentiment and aspect – that can be interpreted and used in different ways.
Data Visualization of the Results
Now for the transformation! You’ve analyzed your customer feedback by running it through a text analysis model, and now you want to present the results in a clear and engaging way to team members. Luckily, there are plenty of data visualization tools out there that you can use. We’re just going to mention a few below:
Google Data Studio
Google Data Studio is a free data visualization tool that allows you to create engaging reports that are easy to understand. Tailor your design by choosing from graphs, pie charts, geo maps, scatter charts and much more. Then share your report or collaborate with team members via Google Marketing Platform.
Looker
Looker is a convenient tool lets you see your data in real-time. Integrations are available through the software’s pre-programmed Looker Block code, making it easy to use and accessible to everyone in your business. It’s also easy to embed modules on websites and apps – a neat integration if you’re looking to impress clients with relevant and up-to-date data. Get started with looker with this tutorial.
Tableau
Tableau is an interactive data analytics and visualization tool that uses a very simple drag and drop interface, making it easy and quick to create reports. It’s compatible with many data sources and is able to handle large amounts of data without impacting the tool’s performance. Check out how to get started with Tableau here.
Instead of presenting a list of numbers to your teams and clients, you can now present an engaging visual. For example, this graph below represents a sentiment analysis of Slack reviews:


Without data visualization tools, you’d be left with a long list of words and numbers in an Excel sheet that are hard to translate into actionable insights.
3. Use Cases and Applications
Now that you’ve created your machine learning models, or at least know how to, you’ll want to know how they can help you boost your business. Auto-tagging with machine learning to analyze feedback has many benefits, a few of which we’ve outlined below:
Routing to the Right Teams
By automatically tagging feedback, businesses are able to organize data and route customer queries to the right teams.
For example, product teams might filter feedback that has been categorized with tags that relate to product features, while support teams could check for feedback that has been classified with tags linked to billing issues. This way, teams are able to be more proactive; there’s no waiting around or scrolling through countless texts. Customer queries can be resolved quickly and efficiently, leading to better customer experiences and higher customer retention. Did you know it costs 5x to 25x more money to acquire a new customer than keep existing ones happy?
Better Customer Insights
Automatically tagging comments related to products and services helps businesses detect trends, and focus on issues that matter most to their customers. Let’s say that the majority of customer complaints focus on Price or User Experience. These would be top-priority issues, which businesses can monitor and resolve in real-time.
Notifications and Proactive Messaging
Instead of checking for tagged feedback, customer agents might want to set up notifications for certain tags, and even create generic auto-responses for queries that occur more frequently.
If a disgruntled customer has complained on NPS surveys showing signs of potentially churning, a pre-set notification would alert customer service agents straight away and they’d be able to take immediate action.
Wrap-up
Businesses can’t ignore the benefits of auto-tagging customer feedback with machine learning.
It’s the only way that they’ll survive in a world that’s saturated with information. Customers expect more from brands and services – faster, more personalized responses – otherwise, they’ll look elsewhere. Businesses have to learn to become customer-centric and understand the Voice of Customer (VoC), which is why tagging feedback is more important than ever.
But it’s no good auto-tagging feedback that doesn’t deliver results. We discussed best practices for tagging feedback and the downsides of incorrectly tagged feedback. And we can’t stress how important this is. Before creating machine learning models, businesses should spend time creating a structure for tagging their feedback. After all, tags are the first step to identifying trends and problem areas within your business.
Once you have your tags in place, then you can train all the machine learning models you want – and trust us, it’s easier if you have a clear set of tags that you can easily apply to your customer feedback.
Why not give it a go now? Write down a list of tags and get started with auto-tagging customer feedback with machine learning using MonkeyLearn. Sign up for free and dip your toes in the water by creating your own models.
Need help getting started? Just request a demo and we’ll get back to you.


Federico Pascual
March 28th, 2019
Posts you might like...












Text Analysis with Machine Learning
Turn tweets, emails, documents, webpages and more into actionable data. Automate business processes and save hours of manual data processing.
Try MonkeyLearn


