

How to Get the Most out of Excel with Machine Learning



Excel is perhaps the most well known data analysis tool out there. It’s used to store and organize data such as sales numbers, profit rates, expenditures or revenues. Some businesses even use it to store text data.
However, Excel is unable to organize text data without the help of machine learning.
Machine learning algorithms can automatically analyze hundreds and thousands of rows of text data in a fast, consistent and scalable way. In other words, machine learning algorithms are able to quantify words and phrases in Excel, by assigning topics, keywords, entities, and even sentiment to each row of text.
In short, machine learning helps teams sift through huge amounts of unstructured data (survey responses, online reviews, emails, and more) in spreadsheets, saving them time and energy and allowing them to focus on more fulfilling tasks.
But what exactly is machine learning? And how can you use it in Excel? Do you need to be a trained programmer? In this article, we’ll cover all of these topics, so sit tight and read on:
- What is machine learning?
- How can it help data analysis?
- How to use machine learning in Excel?
- Create your own machine learning model
- Data visualization of the results
- Use cases & applications
What is Machine Learning?
Machine learning is a field within Artificial Intelligence (AI) that refers to algorithms that allow computers to learn how to perform specific tasks. These algorithms can learn from examples we provide as training data.
An example of a machine learning we’re all familiar with is the algorithm Netflix uses for film recommendations. It shows us movies we might be interested in based on what we’ve already watched. Machine learning algorithms also enable Gmail’s to automatically detect spam in our inbox and Siri to answer questions.
Combined with Natural Language Processing (NLP), machine learning models can effectively understand human-generated text, detect which language it’s written in, what topics are mentioned, or which aspects of a certain service are being mentioned in open-ended responses of a customer survey. These algorithms can even be trained to detect how positive, negative or neutral a particular piece of customer feedback is.
How can Machine Learning improve data analysis in Excel?
So can how machine learning be used to analyze data-filled Excel spreadsheets?
Let’s say you’re sitting on a spreadsheet with hundreds of open-ended responses from a recent customer survey. Extracting insights would normally require hours of manual work. And, in the meantime, urgent matters may come up that require your team’s attention.
Using machine learning to analyze your unstructured Excel data automatically can save your team hours of valuable time and deliver more consistent results. . Additionally, machine learning models can take care of large spreadsheets in a matter of seconds, scaling your team’s productivity upwards.
Real-time analysis of your survey responses could help you quickly craft a product roadmap for your company, addressing urgent issues that might be leading to customer churn. So, the main benefits of using machine learning to analyze text data in Excel include:
- Speed
- Scalability
- Consistency
- Real-time results
Now that we have seen how machine learning is used to analyze Excel spreadsheets, let’s go over the most popular machine learning techniques for text analysis. These can be grouped into two main categories: text classification and text extraction.
Text Classification
Text classification is the process through which tags or categories can be assigned to a piece of text according to its content. It’s one of the most efficient text analysis techniques companies are employing to gather useful insights from unstructured text.
Right now, we’ll explore some of the most popular text classification techniques, including topic classification, sentiment analysis, intent detection, and language detection.
Topic Classification
Topic classification is a machine learning technique with which an algorithm can group pieces of text through a collection of data and assign tags corresponding to different theme categories.
With a topic detection classifier, customer-facing teams can automate processes and get better insights from their data. For example, customer experience teams can automatically route new feedback from customer surveys according to the topic. For instance, they can automatically get results indicating how many survey responses are about their service’s price, performance or even their support team.
For example:
“Navigating through the platform’s menus is an absolute mess”
A topic classifying model can be trained to read this and tag it automatically under “UX/UI”.
Check out this pre-trained topic classification model by MonkeyLearn, designed for SaaS companies to classify NPS responses. The built-in tags here are “Customer Support”, “Ease of Use”, “Features”, and “Pricing”. Just enter your own text and click on “Classify Text”:
Sentiment Analysis
Sentiment analysis is the process through which a machine learning algorithm assigns a specific value to text pieces according to its sentiment, like positive, negative, or neutral.
A sentiment analysis model can sift through a batch of survey responses and tag them by positivity, negativity, and neutrality. This can help many companies quickly get a first glance at their latest survey’s results before actually analyzing them individually.
Another way of using sentiment analysis could be to train a model to detect negative sentiments in survey responses or support emails, to take care of those issues first.
You can check out how a sentiment analysis model works with this pre-trained model:
Intent Detection
An intent detection model can tag a text according to a set of intentions before we read them. For instance, an intent detection model can be used to automatically tag responses to outbound sales emails according to the expressed intent.
This pre-trained model can detect whether our potential customers are interested in our services or not. Subscribe, Unsubscribe, Interested, Not Interested, and Email Bounce are some tags that the models predicts:
Language Detection
Language detection is a natural language processing model which can determine which language a certain piece of text is written in.
Service providers usually have customers from all around the world, with specialized CX and support teams speaking several languages. A language detection model can help speed up the process of driving each support ticket, email, tweet or piece of feedback to the right team without having to check them manually in advance with a localized team.
This pre-trained language detection model can identify 49 different languages. You can test it with your own text and see which language it detects:
Text Extraction
Text Extraction is a text analysis technique used to extract data that’s already in the text. These elements can be keywords, product specifications, prices, and brands, but the possibilities go beyond that.
Let’s go over some of the most commonly used text extraction methods: keyword extraction and entity recognition.
Keyword Extraction
Keyword extraction can quickly let us know the most relevant words or expressions from a piece of text. These keywords can be useful to either summarize what a large piece of text is about or to get back a list of subtopics present in it.
For example, we could use a keyword extraction model in a spreadsheet containing our customer’s feedback and track how many times certain aspects of our products are being mentioned.
Let’s imagine we’re in the electronics market. Another way to use a keyword extractor would be to analyze our ICP’s (Ideal Customer Profiles) tweets or reviews to understand what sort of specs are usually being addressed by our target market.
Check out the following pre-trained keyword extraction model with your own text:
Entity Recognition
Entity recognition models are trained to extract people’s names, brands, companies, institutions, universities, and more from a text. This can be especially useful for brand monitoring, but it can also be used to analyze spreadsheets filled with customer feedback, to see if customers are mentioning the competition or other brands within their comments.
Here’s a pre-trained company extractor that identifies companies and entities from text in English:
How to use Machine Learning in Excel?
Ok! You’re now ready to get your feet wet and start using machine learning models in your Excel spreadsheets.
The first thing you’re going to learn is how to use a pre-trained machine learning model, created by MonkeyLearn.
So suit up and get ready!
Step 1: Explore and Choose Models
Sign up to MonkeyLearn for free, then head over to your dashboard and click on explore. Here, you’ll see a list of pre-trained models for specific tasks:


For this tutorial, we’ll choose a sentiment analysis model. This will help demonstrate how machine learning can play a significant role in analyzing customer survey responses:


Step 2: Upload Your Excel Spreadsheets to the Model
Next, upload your Excel file with the data you want to analyze. MonkeyLearn also supports other file extensions, like CSV, and offers integrations for platforms like Zapier, RapidMiner, and Zendesk.
Now, you’ll need to click on the ‘Batch’ tab and upload your Excel spreadsheet to MonkeyLearn:


Step 3: Check The Results
Once this is done, MonkeyLearn will automatically analyze the file with the selected model, returning a new Excel file with a new column containing its predictions:


And that’s it!
Create Your Own Machine Learning Model
Now that you know how to use a pre-trained model to analyze an Excel spreadsheet, let’s go over a short tutorial on how to create and train your own machine learning model.
Custom models are especially useful if you want to count on a machine learning model that’s tailored specifically for your needs and data. You will have to train it from the ground up, but at the end of the day, it's totally worth it if you want to get the most accurate results.
Luckily, training a custom model is an intuitive and straightforward procedure with MonkeyLearn. The next tutorial will help you learn how to create your own text classifier in a few simple steps:
Step 1: Create a New Model
This time, you’ll need to click on ‘Create Model’ in your dashboard, then on ‘Create Classifier’ and finally on ‘Topic Classification’:


Step 2: Create Your Tags
Now, it’s time to tell your new model which tags you want to use when classifying your data. In this case, we’ve picked topics like Performance, Accounts, and Updates:


Step 3: Upload Your Data
The next step is to upload your training data in the form of Excel spreadsheets. This data will be used for training your model:


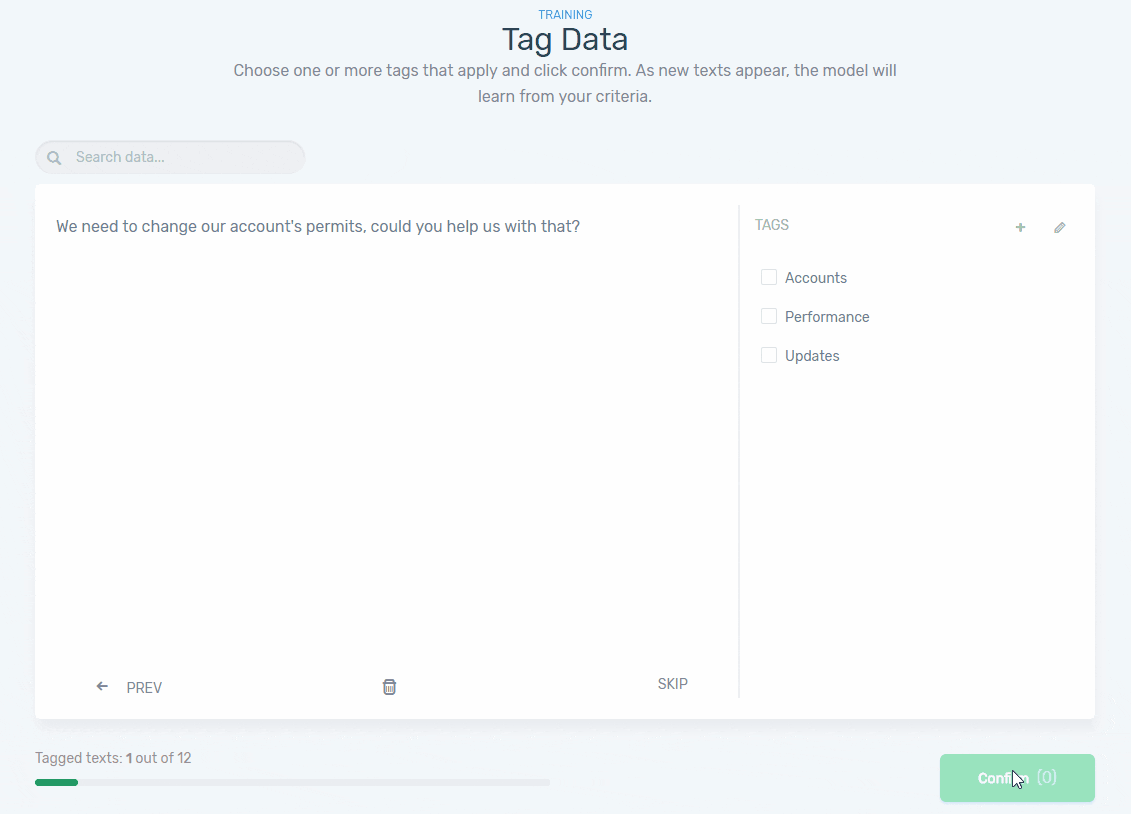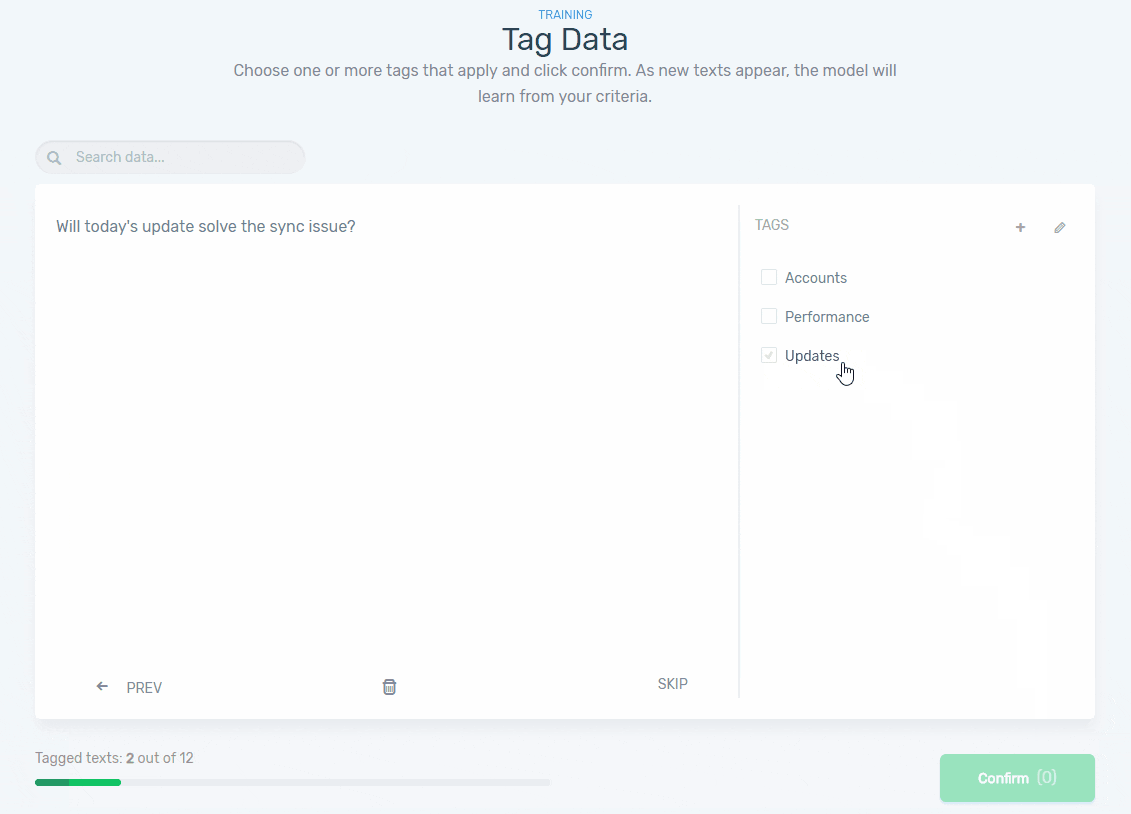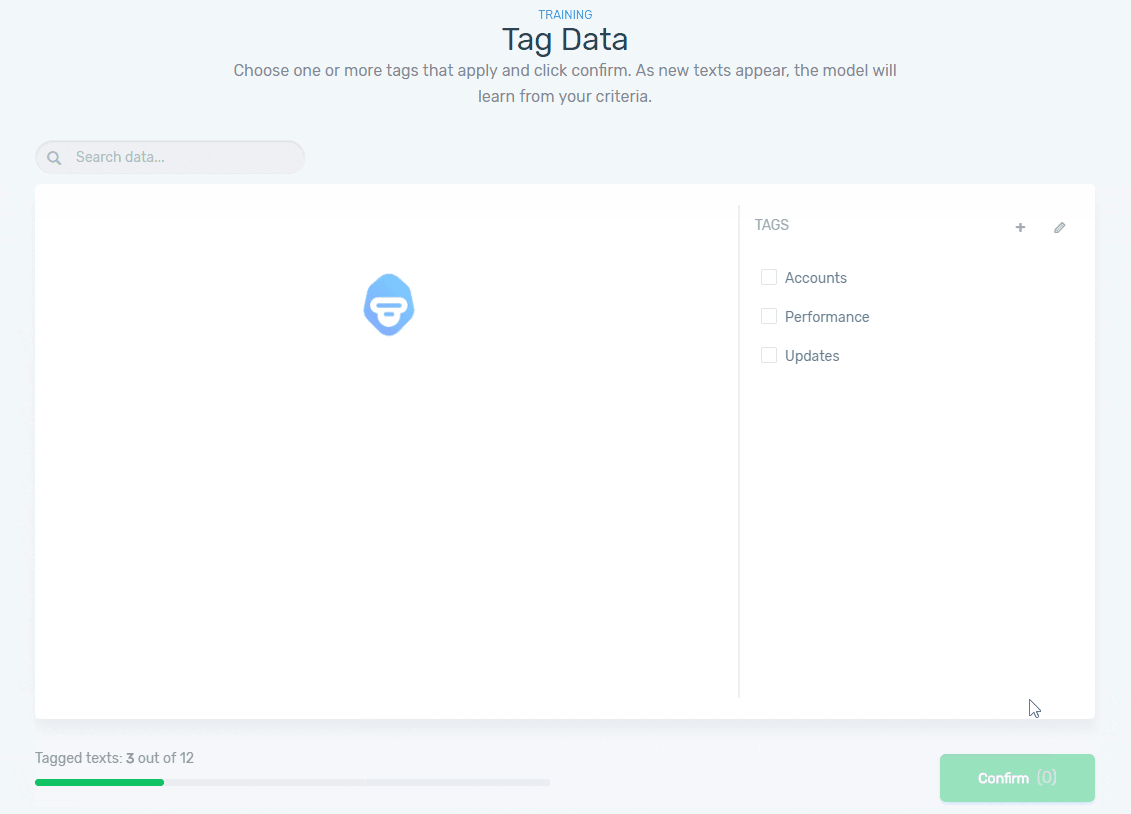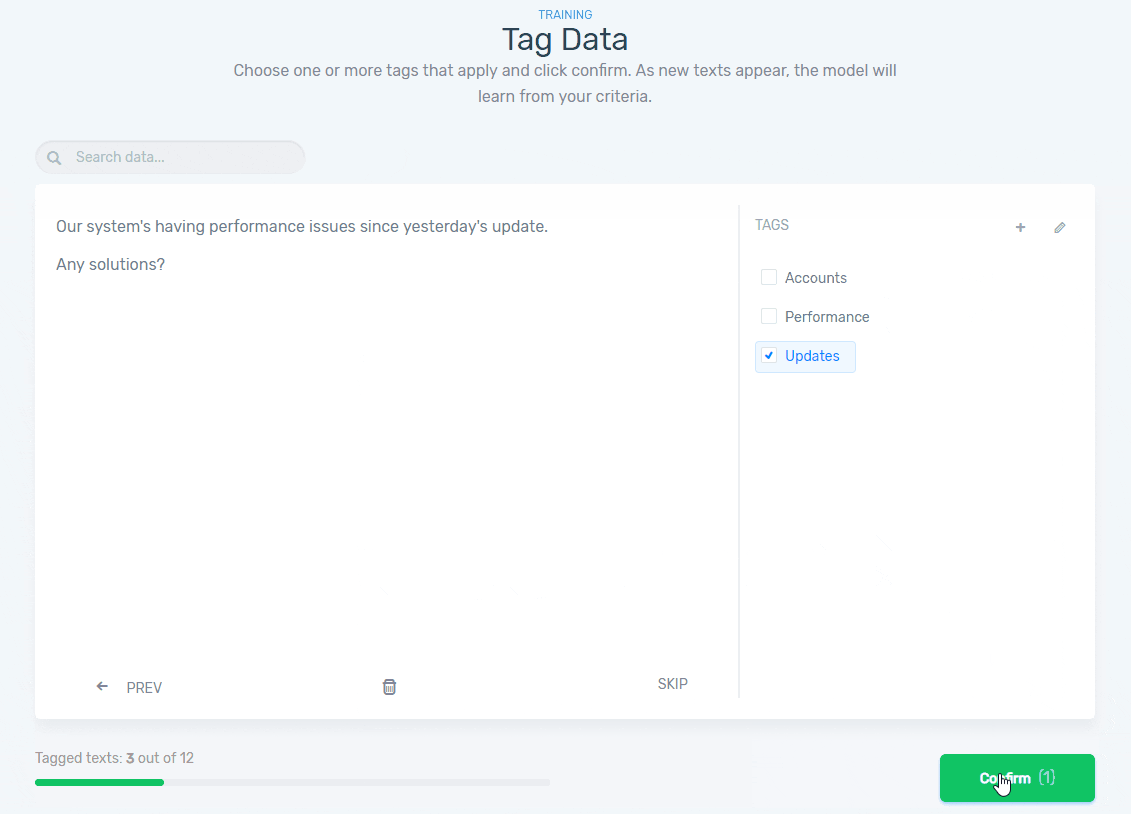
Step 4: Train Your Model
Now, it’s time to train your model by manually tagging some examples so the machine learning algorithm can begin to understand your criteria. Once a minimum amount of samples have been tagged, MonkeyLearn will start suggesting tags:
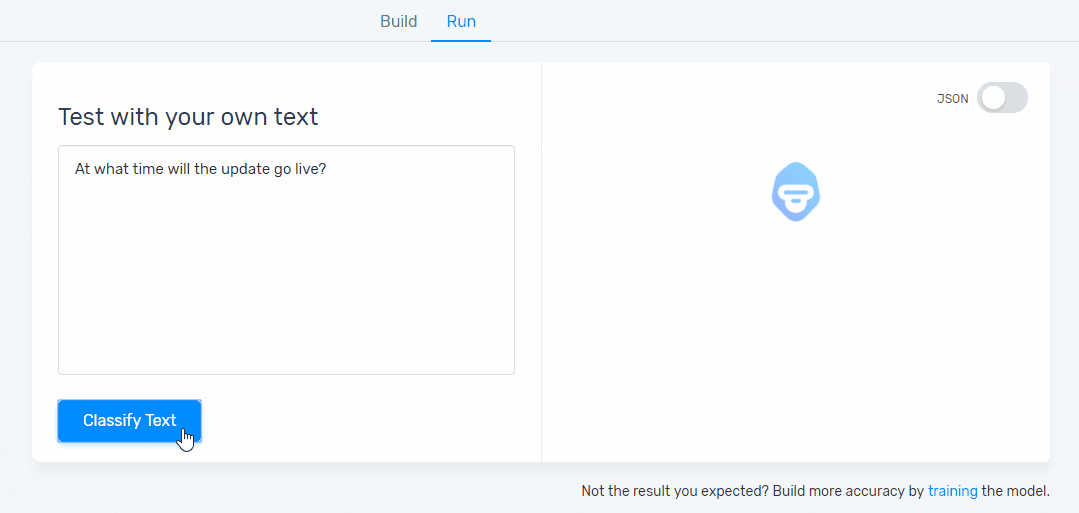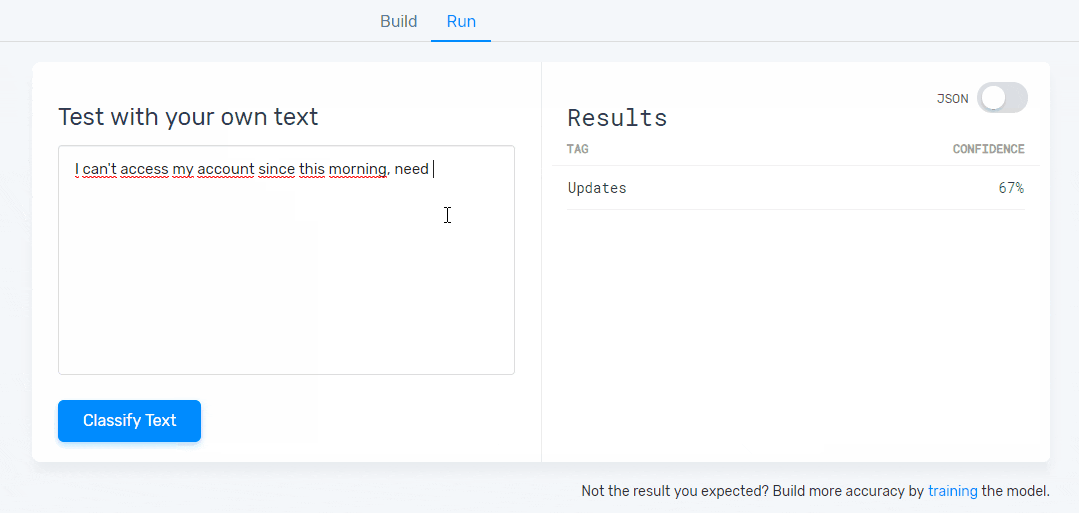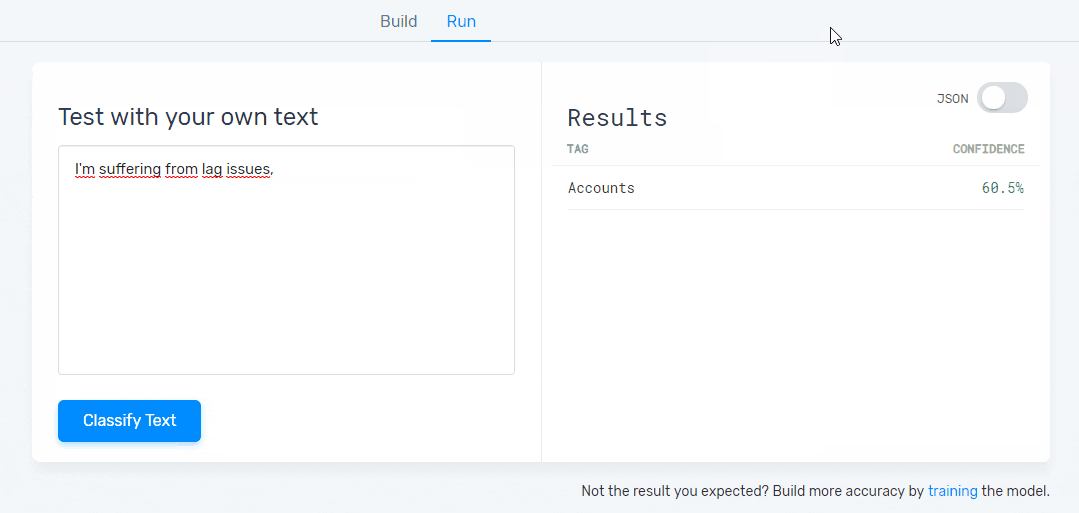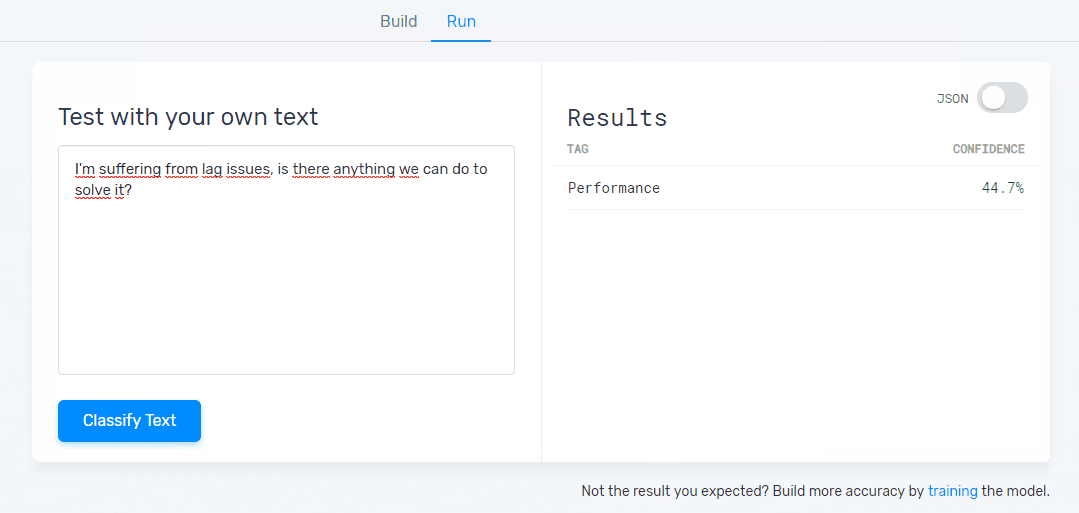
Step 5: Test Your Model
Have a go at writing some feedback to test your classifier. You’ll be able to see your model predict the topics that are present in that particular piece of text. If you see some mistakes just click on the ‘Build’ tab and keep training it. The more you train it, the better your results will be:
And that’s it! You now have your own, custom model to start classifying your Excel data in an efficient, scalable, and fast way. Remember, the more you train it, the more accuracy you’ll see in the results.
Data Visualization of the Results
Once all the text data in your Excel spreadsheets has been analyzed, you’ll probably want to visualize the results in a way that allows you to get a clear picture of your customer insights.
Excel has built-in tools to create charts and graphs that are super useful for getting insights right away from the results of your analysis:


There are dozens of different charts for visualizing results on Excel, and even more ways to slice your data for visualizing different aspects of your analysis. So, it’s important to first take a moment and define the insights you are looking for. Then, the next step is to find the graph or visualization that best fits your needs.
But Excel is not the only tool for creating engaging visualizations that you can share with your team. Next, we’ll explore three popular data visualization tools that easily integrate with Excel spreadsheets.
MonkeyLearn Studio
Perform text analysis and data visualization all in one place with MonkeyLearn Studio, and get fine-grained insights in real time. You can also connect MonkeyLearn’s tools directly to Zendesk, so you can gather data on the go, without having to import your text to a spreadsheet and upload to MonkeyLearn’s models. This is a great option for those that have huge amounts of data to analyze.
Check out this topic and sentiment analysis performed on online Zoom reviews:


Google Data Studio
Launched in September 2018, this is one of Google’s latest services and consists of an intuitive yet deep data visualization platform designed to create attractive presentations from our data.
With Google’s trademarked simplicity, Google Data Studio has a pretty low learning curve and can deliver static and interactive charts, graphs, and maps.
One of its distinct features is its seamless integration with Excel. Once we have connected data from an Excel file, there’s no need to re-upload it if we add data or make some changes. Google Data Studio stays connected to your data and reflects any changes in your presentations.
Last, but not least, it’s free!
Here’s a tutorial on how to get started with Google Data Studio.
Tableau
Tableau has a steeper learning curve but holds a large number of integrations, allowing us to connect our data from almost anywhere. Although you’ll need a paid subscription, Tableau also offers guided tutorials and free trials to familiarize yourself with the platform. Tableau also provides useful dev tools for a more in-depth approach to data analytics.
One thing to keep in mind is that Tableau’s repertoire of charts and graphs isn’t as extensive or versatile as one would hope for. Also, it’s performance can be a bit clunky at times, but it still remains as one of the most used data visualization tools in the market.
Looker
Looker’s learning curve is at that middle spot between Google Data Studio and Tableau, offering easy-to-use interfaces and a diligent support team for any questions that might arise.
With Looker, any business can reflect insights from large spreadsheets with style and ease. Prices range depending on the customer, so there’s a personalized aspect of their service. Either way, product demos are available for anyone wanting to check out Looker before making a decision.
Looker’s branding often revolves around ‘the bigger picture’, and that’s why its platform has a pretty big catalog of visualization options and ways to integrate our data.
Here’s a handy tutorial on how to use Looker’s basic features.
Use Cases & Applications
Now, let’s take a look at how machine learning in Excel can help your business:
Customer Feedback
How many NPS responses does a company receive each quarter? Hundreds? Maybe thousands? Most customer surveys are easy to analyze, but open-ended answers are harder to batch-process because the data in them is unstructured. It consists of natural language in the form of sentences that machines are unable to understand.
With the proper training, sentiment analysis, topic classifier and keyword extraction models can automatically read NPS responses and provide accurate insights on what is being mentioned and how (sentiment).
For instance, Promoter.io used a keyword extractor to analyze their NPS responses and quickly visualize how many times different aspects of their service had been present in those responses:


This graph shows that Promoter’s service is the undisputed star of their NPS score, followed closely by quality and great service. This last keyphrase is interesting because we can trust that almost every time we see it in a piece of text it will be positive.
Market Research
Brand awareness, user engagement, and prevailing trends are some of the main things a brand manager usually looks for when trying to understand the different narratives. Social media holds valuable information about your brand and your competitors.
With keyword extraction, you can quickly identify the main concerns or conversation topics approached by your target audience on social media. This process can also be done on any other unstructured text source like, for example, customer review sites such as Capterra or G2 Crowd.
In this post, we analyzed nearly 1 million hotel reviews from TripAdvisor. The results were more than interesting.
The first thing we did was to use a sentiment analysis model to divide reviews into good and bad:


After that, we filtered the results by city and obtained a more in-depth overview of which cities around the world receive the best and worst reviews by their customers:


The results showed that London has the overall worst reviews among other big capital cities around the world. Bangkok and Madrid hold the best records so far.
But we went even deeper. With topic classification, we were able to see which are the most mentioned aspects by these customers and in what sentiment across the different cities:


Based on these results, London’s hotels should urgently review ‘comfort and facilities since this aspect receives the most negative reviews in the 1 million pieces of customer feedback analyzed. On the other hand, Bangkok’s hotels seem to be doing very well in this aspect.
Parting Words
When you need to analyze text data stored in Excel spreadsheets, and look for trends regarding topics, keywords and even sentiments, there’s not much Excel can do.
With machine learning, all of that stored data can be processed in a scalable, fast and easy way by an AImodel that learns from experience. You’ll save time and money and relieve teams of cumbersome tasks.
Customer experience, product, customer support, and many more teams can use machine learning in Excel to make their jobs easier. And with ready-to-use tools, like MonkeyLearn, you don’t even need programming skills.
If you’re interested in getting started with machine learning in Excel and beyond, request a demo and we’ll show you how to get started.


Federico Pascual
May 24th, 2019
Posts you might like...












Text Analysis with Machine Learning
Turn tweets, emails, documents, webpages and more into actionable data. Automate business processes and save hours of manual data processing.
Try MonkeyLearn


